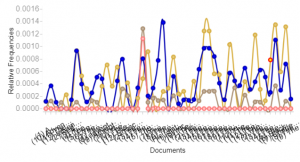
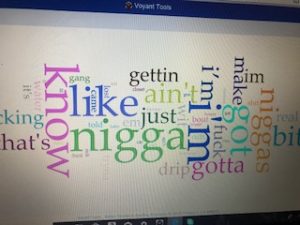
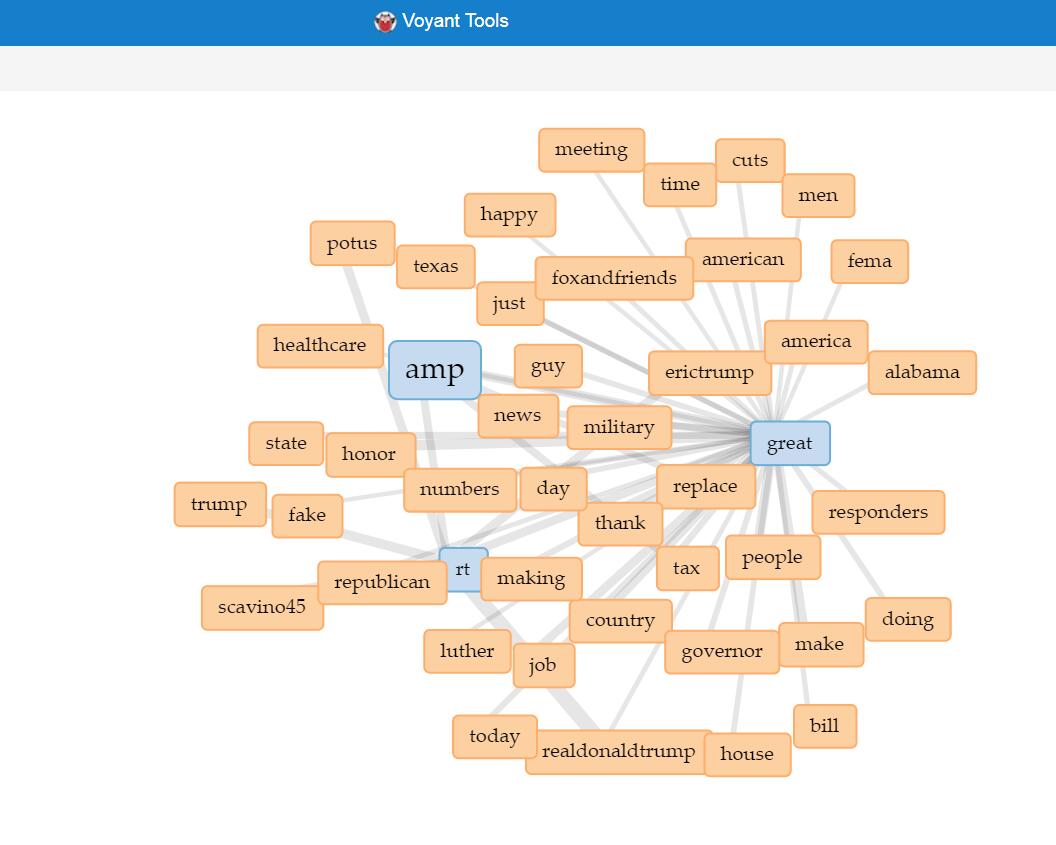
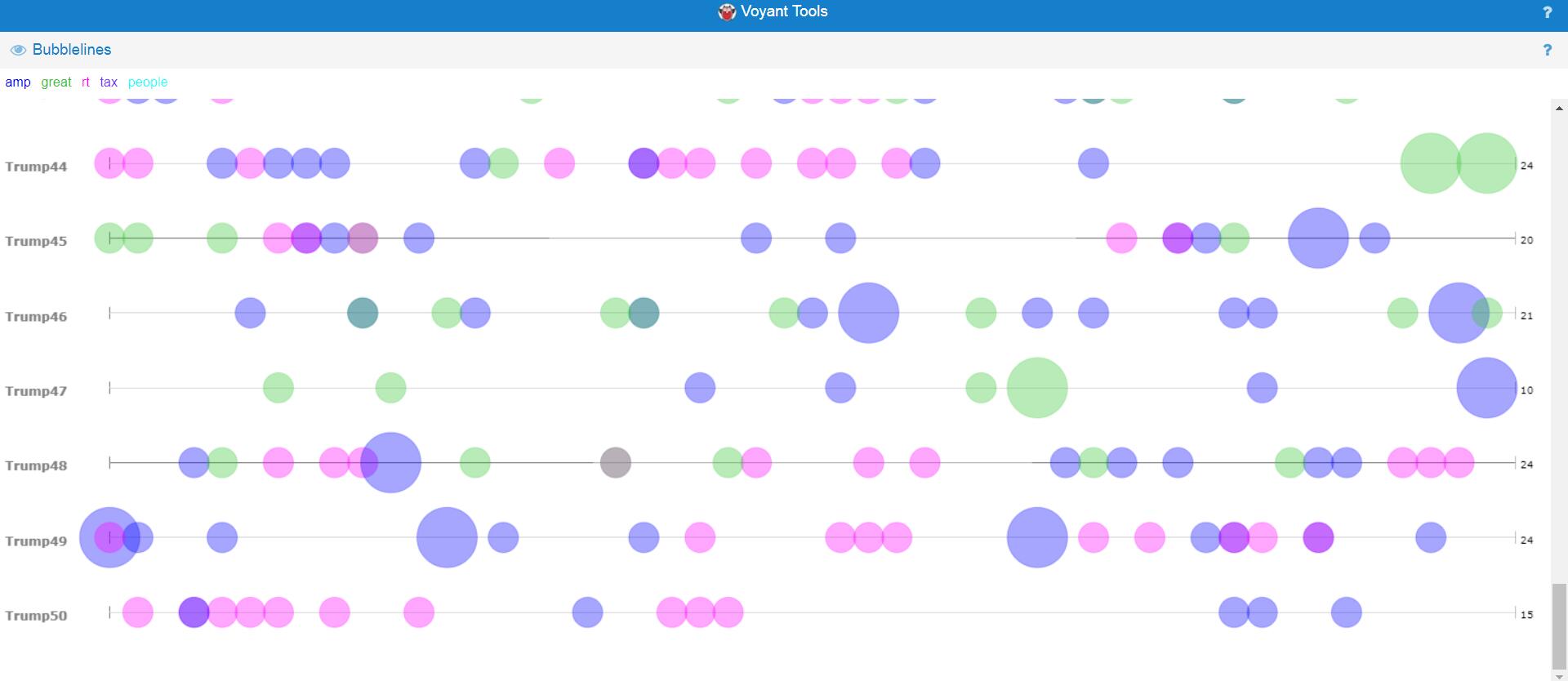
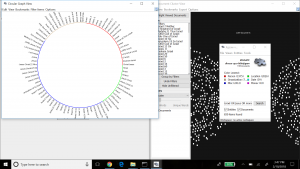
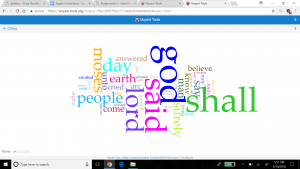
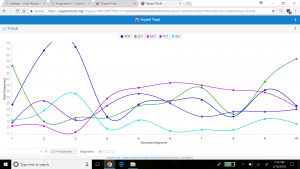
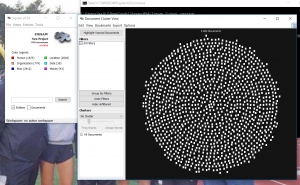
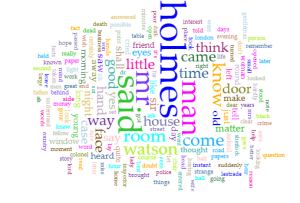Through the past decades, hip-hop and rap music has evolved into many styles as new groups have formed and changed the culture. Being that music has a major impact on my daily life, I decided to create a song corpus from my favorite tunes/artists. One goal that I want to accomplish is to gain a better understanding of the content that these songs entail. I will be using the albums Culture 2, Young Rich N****, and Too Hard. The corpus artists’ (Migos: Quavo, Offset, Takeoff), Post Malone, Baby, Two Chainz, and Drake) originated all across Atlanta, Toronto, and Syracuse, NY. With New York and Atlanta being popular musical city hotbeds, I felt that this would give a provide an interesting comparison while deciphering the similarities that these artists have while expressing their lives through words. The lyrics include a few explicit words which give my corpus a realistic feeling which reveals the true identity of this genre. My overall corpus construction worked well with both tools as it discovered word frequencies as well as comparisons regarding the main words and phrases. I have used Voyant many times throughout my time at Bucknell and it has been outstanding, to say the least. It allows a viewer to gain a better understanding of the text in a variety of ways and methods. Since there are many options to choose from, the creator isn’t limited to a standard format which helps a corpus true meaning to be shared with the intended audience. I chose Mandala and Trends which connected the words together between songs and highlighted the connection of the song-to-word. Mandala has a clean and basic appearance that vibrantly lights up when you move the cursor across the song title. Trends was a bit different as it displayed the frequency in which the words were being used. This showed revealed the artist’s favorite rhyme scheme or lyrical pattern.
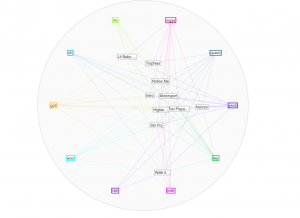
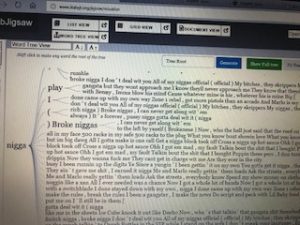
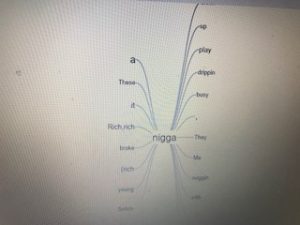
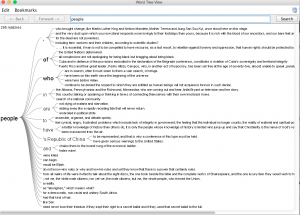
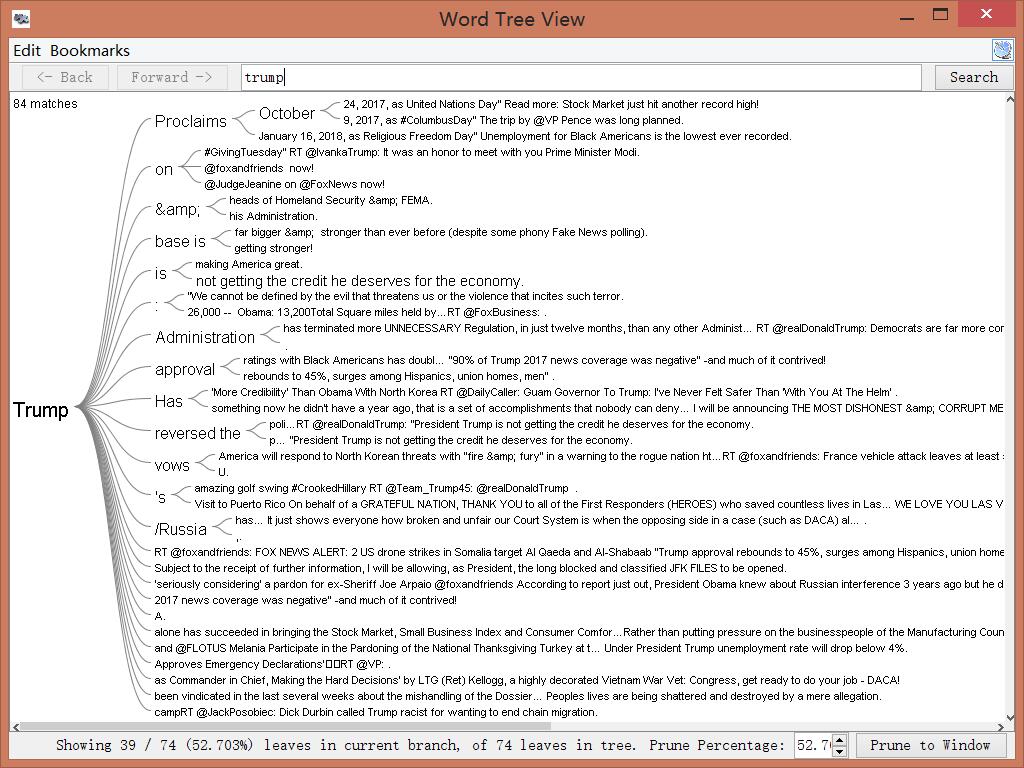
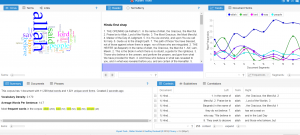
After using both platforms to visualize and analyze the corpus, I can see that they both have many similarities between the two, however, they are very much different at the same time. Using the Word Tree file in Jigsaw, I highlighted “money” as the keyword which is a common topic of discussion regarding the dream rap artist lifestyle. Voyant showed me the similar linked words to money within a song. Jigsaw actually connected phrases and linkage which created an extensive amount of data. It showed an artists lifestyle, his goals and what his future plans would be with the money, also about the violence surrounding their life in order to generate and maintain this currency. It’s also as if it goes deeper than the surface of a lyrical pad and actually tells a story of its own in a unique way. This connects an audience to an artist life which they can then relate it towards their own personal life. By using Jigsaw, it’s possible to reveal similarities that you’ve never known about an artist. For instance, in the Migos’ project Young Rich N*****, this was the early stage in their careers where it was understandable that they showed immaturity in their raps as they related money back to strip clubs and drugs. However, their Culture 2 album showed that money related to conducting businesses, establishing great credit, and creating lives for their family members. Both platforms effectively conveyed forms of a relationship between artist and style/slang. Mandala revealed that the terms ‘yea’ and ‘woo’ where the most found terms which are interesting because, at the end of many verses, the artists use those words as ad-libs to transition into the next verse or stanza. This contributes to the melodic vibe that’s created when making this kind of music.

Ultimately, this corpus construction and visualizations has further supported Tanya Clement’s observation’s as I was able to create “multidimensional viewpoint” by using the tools. Instead of being stuck in one category, these platforms have allowed the viewer to analyze an artist beyond the lyrics while actually using the content given in their songs. It’s very ironic that these songs have come to life while never actually having the livelihood, to begin with. It now jumps off of the paper and into our minds where we can now view information from all different angles. Also, using these tools strips the narrative or delivery from data and only shows textual word. Both platforms invite the viewer to analyze and interpret data in a creative way which wouldn’t be possible by just an ordinary viewing.