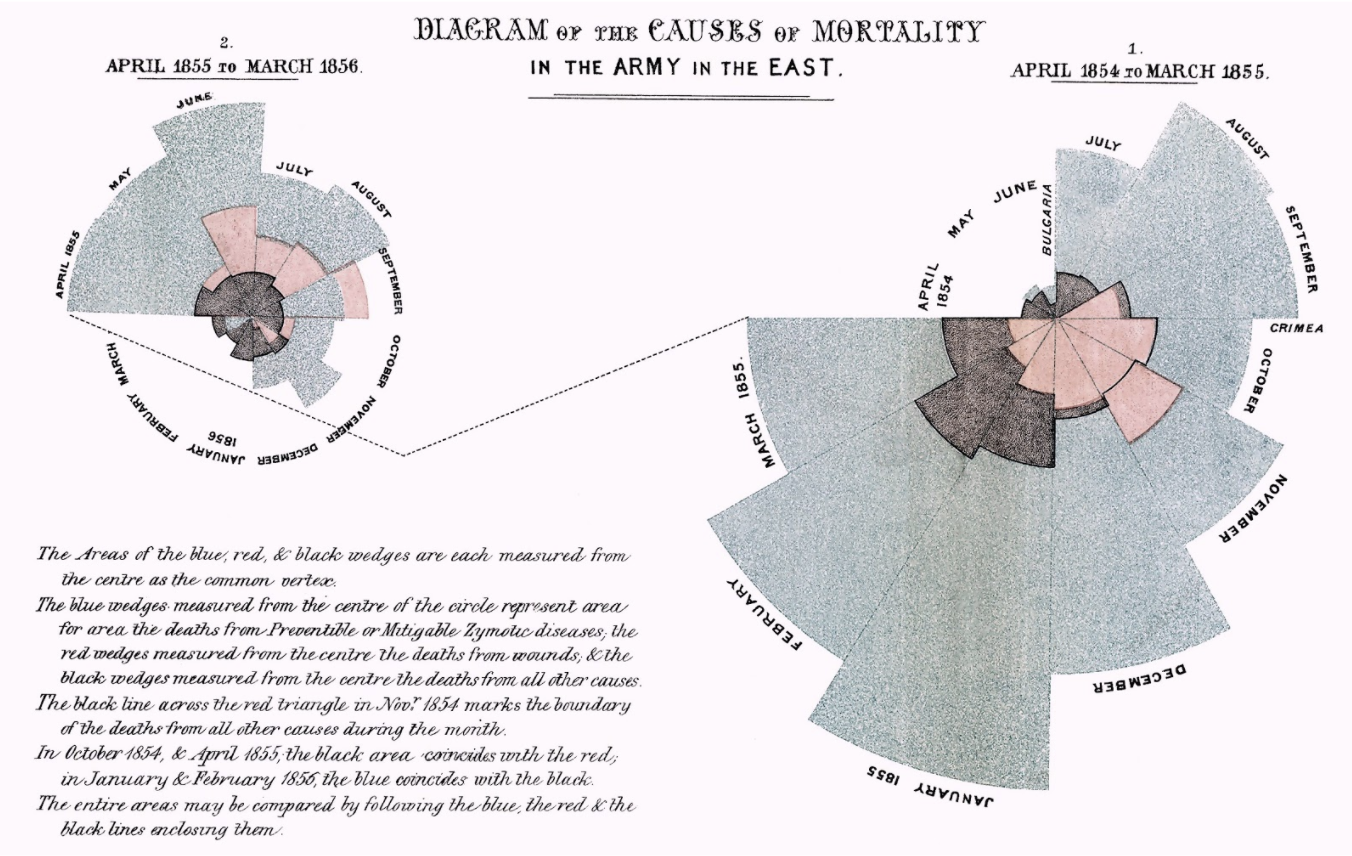
“Diagram of the Causes of Mortality in the Army in the East” (Florence Nightingale, 1858).
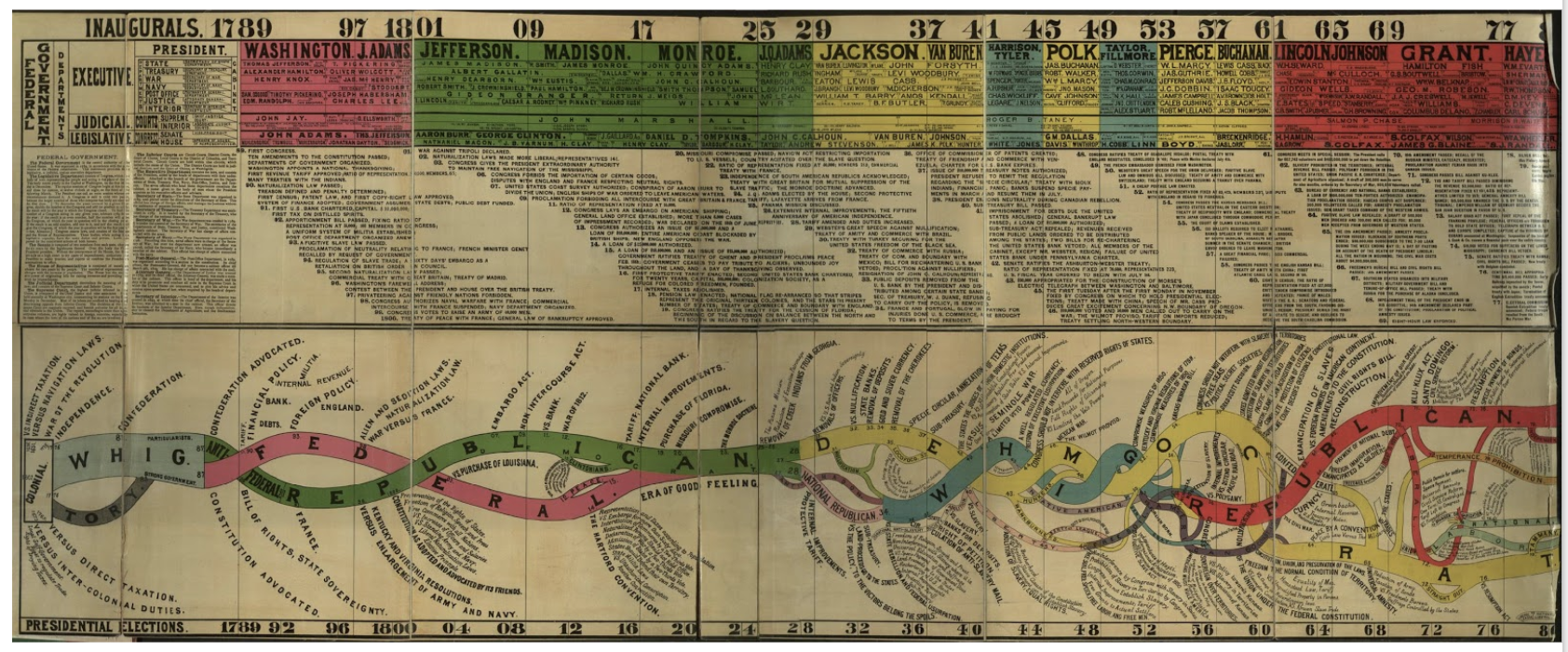
“Conspectus of the History of Political Parties” (1880).

“Last Clock” (Jussi Angesleva and Ross Cooper, 2002)
“Diagram of the Causes of Mortality in the Army in the East” (Florence Nightingale, 1858).
“Conspectus of the History of Political Parties” (1880).
“Last Clock” (Jussi Angesleva and Ross Cooper, 2002)
“Linear Chronology, Exhibiting the Revenues, Expenditure, Debt, Price of Stocks & Bread, from 1770 to 1824” by William Playfair

The different color lines are different categorical variables of the data such as the revenues, expenditure, debt, price, etc. Historical events in time are shown on the horizontal axis. It shows how they changed over time from 1770 to 1824. I thought this would be really interesting because it shows a lot of categorical data on one timeline and it shows the connection between them all during any given moment in time. This would be useful for my data of the Death Row Inmates because I have so much metadata about them, such as where they are from, what race they are, what they said, what they did, their age, their education level, and their gender. Seeing all of this information over a period of time and seeing how it has changed since 1982 would be very interesting to analyze. In the platforms we’ve used, like Palladio, I haven’t been able to look at all of these in one space or one timeline. This would give me insight into how the types of prisoners that we see on Death Row have evolved over time.
This visualization was interesting and very well organized. I figured it would be interesting to categorize the crimes committed by the prisoners sentenced to Death Row or even the racial breakdown. I think it would be beneficial to look at this over time, from 1982 until now because it could show how the crimes have changed over time.
https://www.bls.gov/tus/charts/students.htm
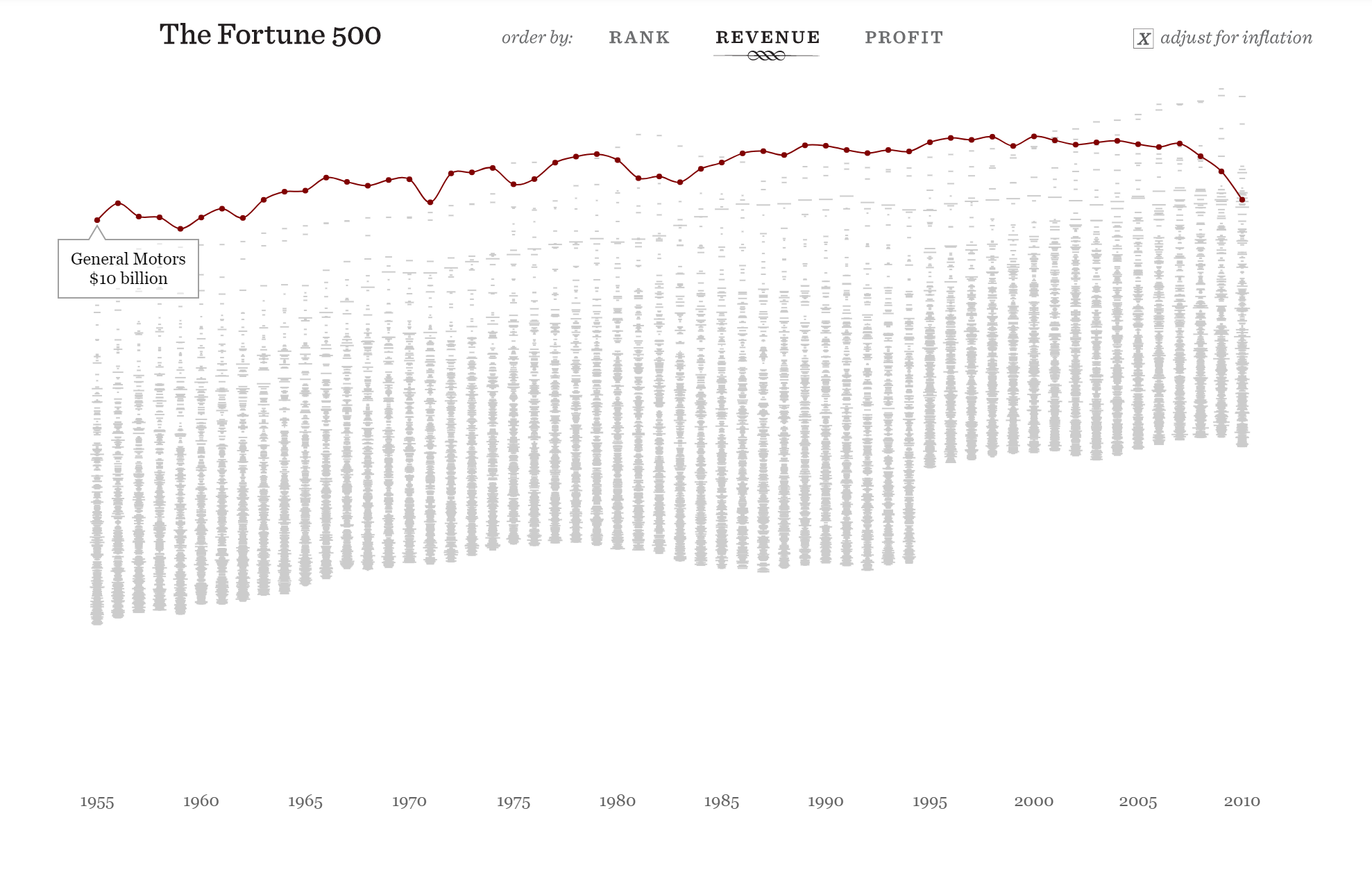
https://fathom.info/fortune500/
https://flowingdata.com/2015/12/15/a-day-in-the-life-of-americans/

[gview file=”http://humn2702018.blogs.bucknell.edu/files/2018/03/presentation-for-32F62F18.pptx”]


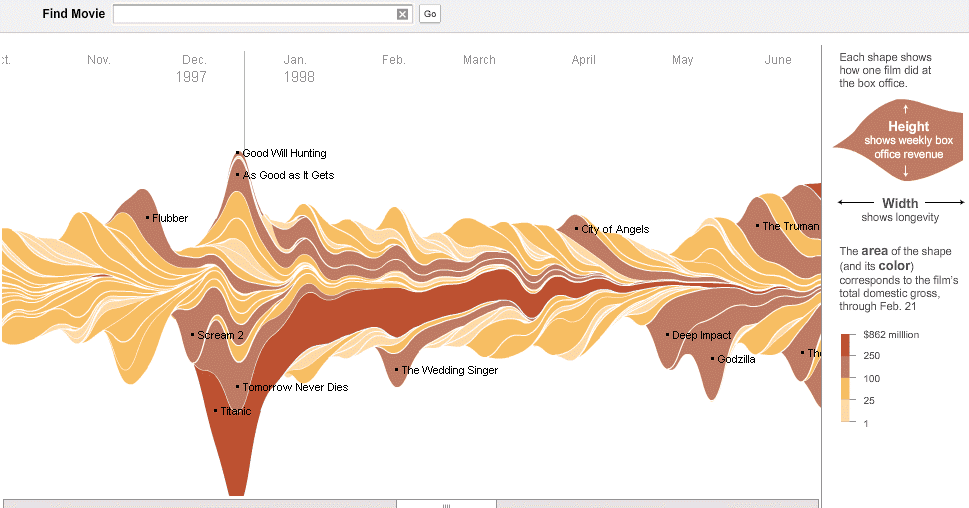
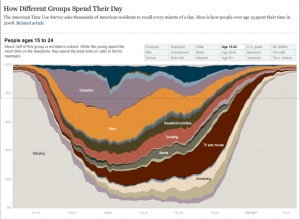
I chose this stacked flow visualization regarding ticket sales because I think it would be rather illustrative in the context of my data. I believe I could select one or more journalistic publications and collect information regarding the volume of articles written about Penn State over the course of several months, beginning in November 2011. In order to separate out layers as shown above, I could potentially differentiate articles by subject (ex: Sandusky, Paterno, football program, university, etc.) and see how volume ebbs and flows over time. I believe this visualization would help to depict the nuance of the narrative of scandal I am looking to depict. For example, I believe certain subjects will have their volume increase at certain points, showing turning points in the scandal (ex: Paterno’s volume will likely increase around the time of his death or the publication of the Freeh report).
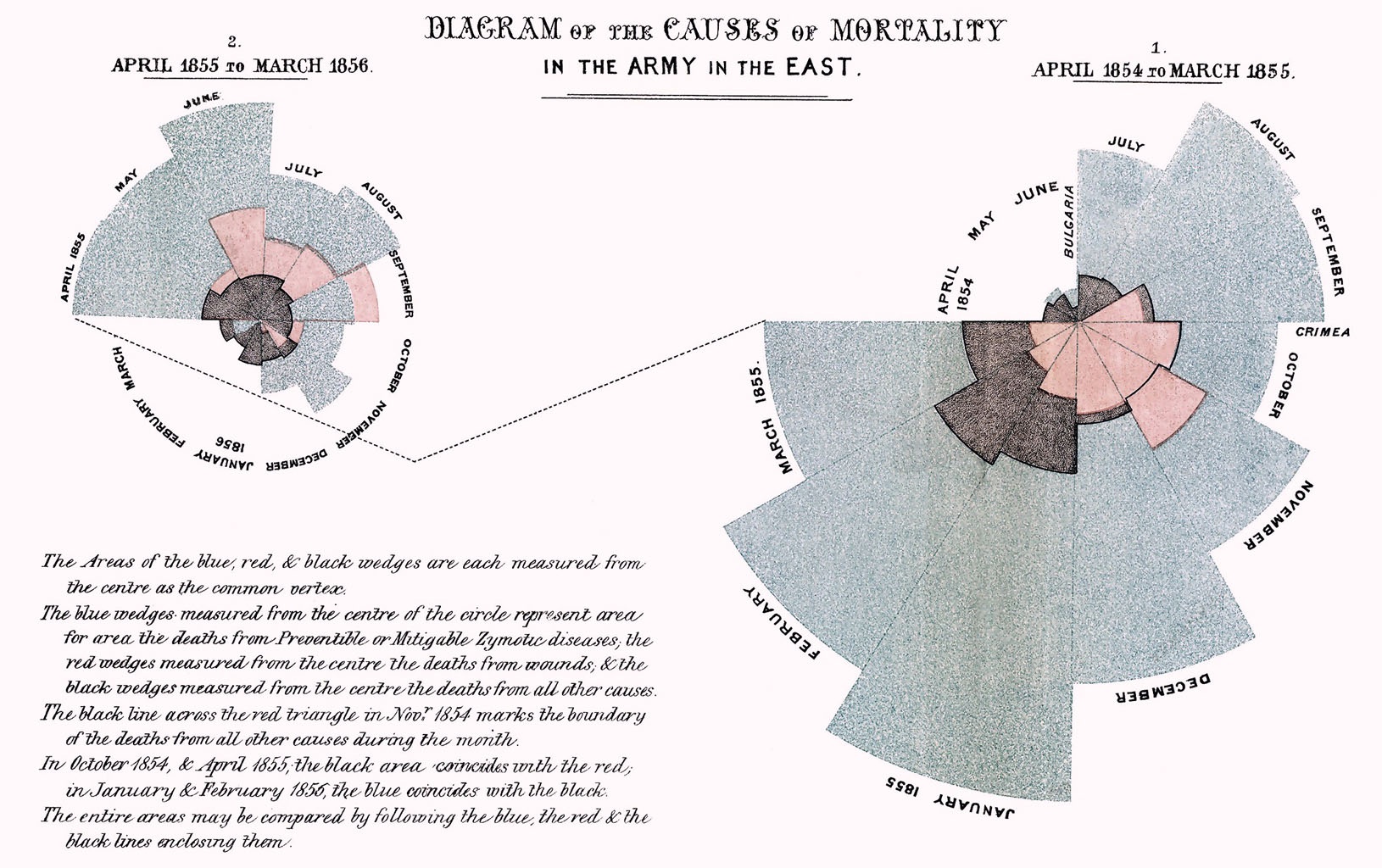
Florence Nightingale’s radial diagram could also be useful in visualizing the time dimension of my data (article publication date) as the pedals can expand to show volume, but also be broken up into actors, similarly to the layers of a stream graph. In addition, the circular layout of the visualization implies a repetitive aspect that would be interesting to incorporate should I choose to compile volume data for more than a particular year.
My data set is a collection of text documents (mostly speeches with a few recorded statements orations) regarding civil rights, delivered by a variety of divers authors. The authors include a Native American Chief from the 1850’s, Martin Luther King Jr. and even 2016 presidential candidate Hillary Clinton. In my data table I have included the descriptor categories:
Date
Author
Speech Topic/Context
Gender of Author
Location of Speech
Image of Author.
I felt like by using this combination of data, I could organize these texts in ways that would be meaningful for comparison and allow a reader to draw connections/ recognize similarities and differences between related topics and speeches.

Above is a screenshot of a visualization I created on Palladio using the Graph tool. It links each speech with it’s latitude and longitude and shows which ones were given in the same location. It can also be filtered with the facet tool to show just certain speeches based on gender, topic, etc. The spatialization of this data provides a visual map for a reader with two dimensions that can be controlled to make inferences about whatever is desired to understand.
This next visualization is a mapping tool that shows the location of each speech’s delivery point on a world map. While this is a useful tool as it allows for the spatial awareness of a specific location to become perceivable for the reader, I feel it has some drawbacks as well. First off, the map is not labeled well at all, so without an extensive knowledge of geography, the map cannot stand alone well. Also, the large scaled dots are useful in the sense that they communicate volume of speeches given in a specific location, but they do not have a visible center and they span too large of areas to pinpoint the exact spot even if one did know exactly where that was on an unlabeled map. Google fusion tables has a similar feature and I feel that it does a better job although I have not completely figured out how to use it perfectly yet either.
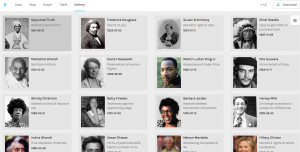
Above is my favorite of the tools I was able to use on palladio, the Gallery tool. It provides a template for a display of multiple pieces of information in a card-like format. As you can see, each card has a picture of the author of the text that it represents, along with the topic/context of their speech listed beneath their name. The cards are also organized by date (which is also listed visibly) to form a timeline of sorts within the larger visualization. Upon clicking on each card, it will also link the reader to a full text of the speech given by that author which allows for the further exploration and adds an interactive piece to the visualization to promote deeper research and understanding. I feel that there have been a vast number of times in my life when it would have been very useful to understand how to use this tool; both to sort information for my own purposes, but also for the ease of presenting it to other people.
As far as Drucker’s distinction between “knowledge generators” and “representations” I simply do not like these mutually exclusive classifications. I believe that something can be both at the same time. I think that these visualizations and this platform (palladio) embodies this idea of duality very well. Am I representing a form of data that already exists through a series of templates? Yes, and in that sense it is a representation. But by compiling this data, formatting it in accessible, user friendly ways, and then making it interactive to promote further examination and learning, I am also generating knowledge by was of access and opportunity. I find this to be very valuable and I think that it is certainly a noble pursuit.
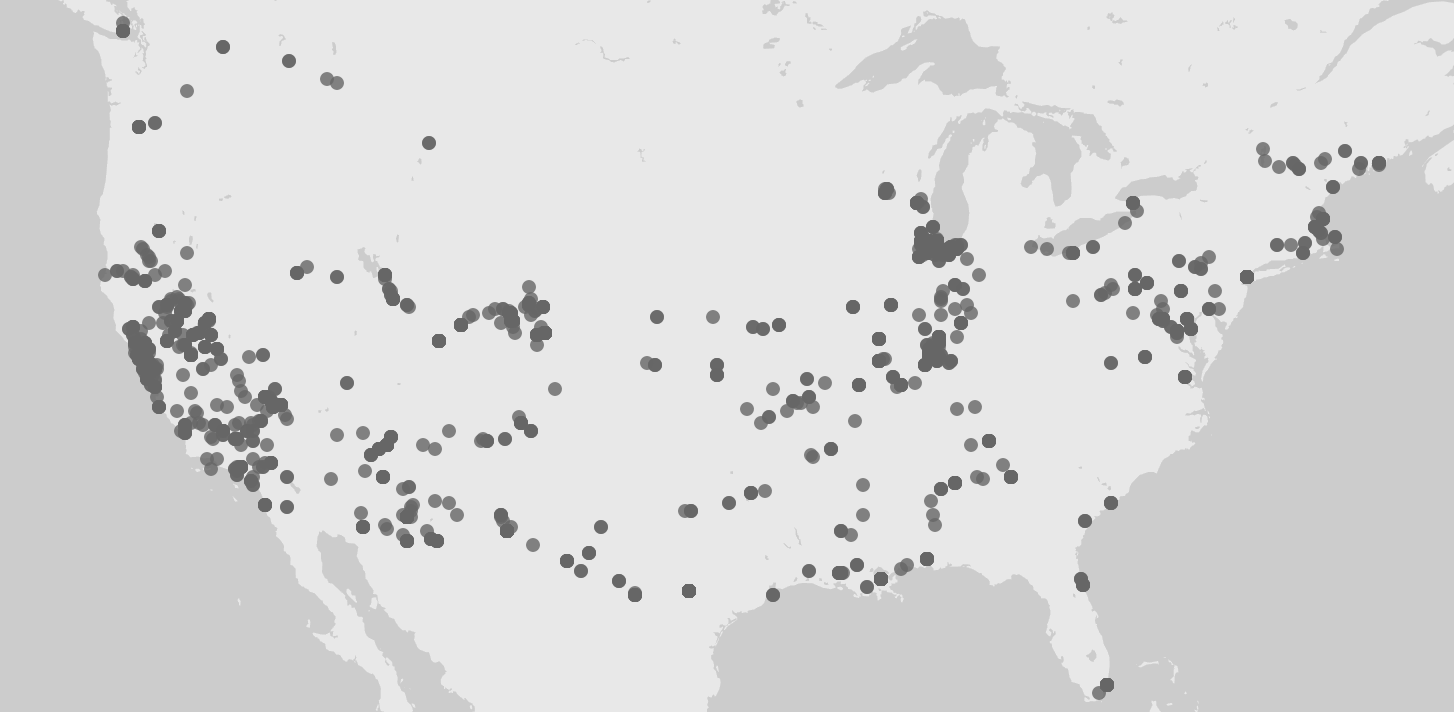
For this assignment, I used the meta data of the Charles Weever Cushman collection of photographs. Looking at the platform of Palladio, I really wanted to take advantage of the map tool and try to take a look at potentially where each of these photos were taken. From this meta data, I extracted about 1000 points of information and input it into Palladio.
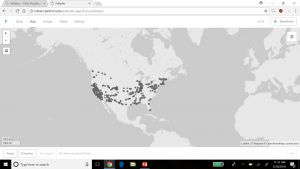
This was an interesting way to view where many of the pictures were taken in the United States with each dot representing an image. It was easy to understand if that was all I wanted to know. But unfortunately, just the dots alone were not very easy to understand. This view mode lacked the detail. The detail I was looking for was exactly where each photo was taken, maybe a town name or relative location. Therefore, I did not have too much to go on other than a general location. For the sake of comparison, I decided to do the CSV file in its entirety in Google Fusion Tables.
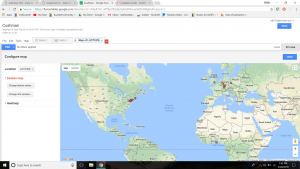
Results were immediately improved. Google Fusion Tables gave me the names of the states, their boundaries, and an easier was to select the dot of information and understand what was being represented in that specific dot. Although both tables of information showed a stronger gathering of images taken on the west coast and northeast, Google Fusion tables allowed for much more detail. Google Fusion allowed me to understand and interpret my data much more effectively. I wanted to use the timeline feature of Palladio as well, so I used that to determine when each picture was taken on Charles Weever Cushman’s journey.
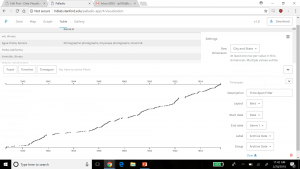
This was interesting to look at because one can see when Cushman was the most active in his journey. Understanding the time of which each picture was taken could tell a researcher where a point of interest might have been at that time. This is where Drucker’s analysis on how to create new ideas from demonstrations can be seen in both the time line and map features of Palladio. Researchers looking at the trend of where and when the pictures were taken could introduce new ideas into what they were investigating, especially if both have a trend to peak interest from Cushman (taking more pictures/spending more time in that area). Palladio is a decent platform for getting this kind of data, but perhaps with a little more detailed input, such as location and state lines as seen implemented in Google Fusion Table’s, Palladio results could be a little more fulfilling to a researcher.
In creating my data set, I chose to look at the Fox TV show, “New Girl” and to analyze various aspects across the different episodes, including views, ratings, and descriptions of the episodes in correspondence to when the episodes were produced and the order in which they occurred in the season.
The raw data itself can be seen here. It consists of all episodes, directors, writers, genders, air dates, U.S. viewers, length, IMDb rating, images, and episode descriptions.
Due to the capacities of Palladio and Google Fusion, I decided to create visualizations of individual episodes and highlights of information with those, as well as various visualizations about the connections and correlations amongst data. In analyzing these connections, I used the season, release date, number of U.S. viewers and IMDb rating of each episode.
These aspects of each episode were chosen to as representations of each episode, therefore each visualization will have an inherent bias. As stated in Drucker’s work when discussing data in visualizations as capta, she states, “Capta is constructed and not given…the initial decisions about what will be counted and how shape every subsequent feature of the visualization process.” (244) This idea of data as capta must be considered in the graphics below, as the information and ways to present it was chosen by myself and therefore is no longer pure data.
All visualizations created both through Palladio and Google Fusion. The main goal of using these tools was to communicate the “New Girl” metadata through various graphic designs. As Drucker states, “Communicating the contents of a digital project is a knowledge design problem – since the multifaceted aspect of database structures offers different views into the materials.” (243) Because of this, multiple visualizations were created to allow for different perspectives on the data itself.
Below are various creations of visualizations done in Palladio.
This first visualization was created using the Gallery function. The main purpose of this graphic is to give the viewer a visual and quick way of reference to each episode. One lacking feature to the Gallery function is that there should be a way to include additional information to the cards, because while I believe this visual is functional, it’s not the most effective at communicating all aspects of each data point from various aspects.
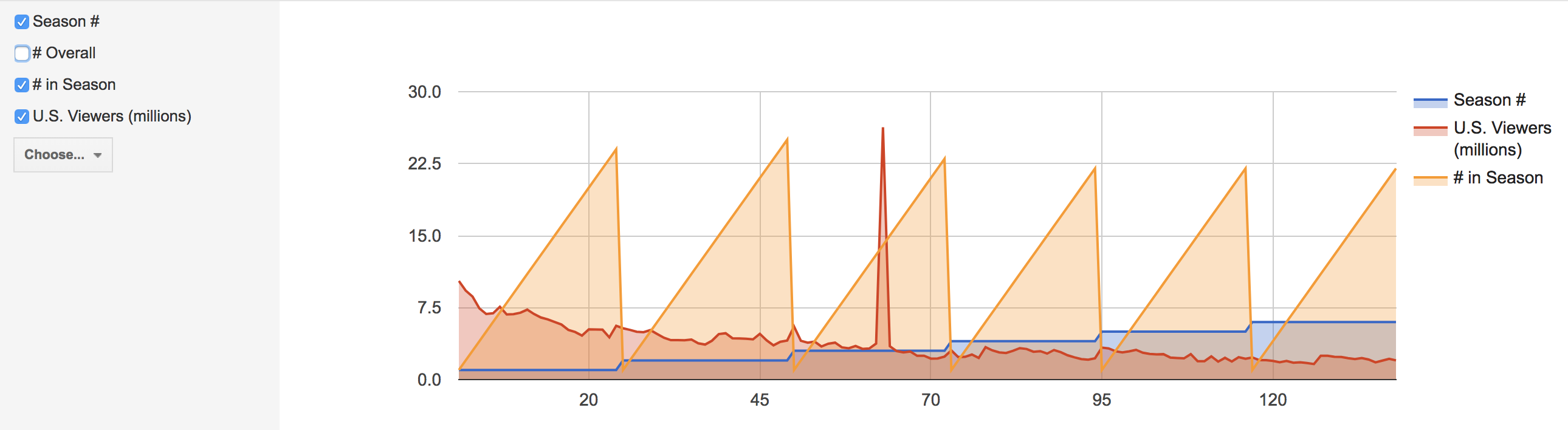
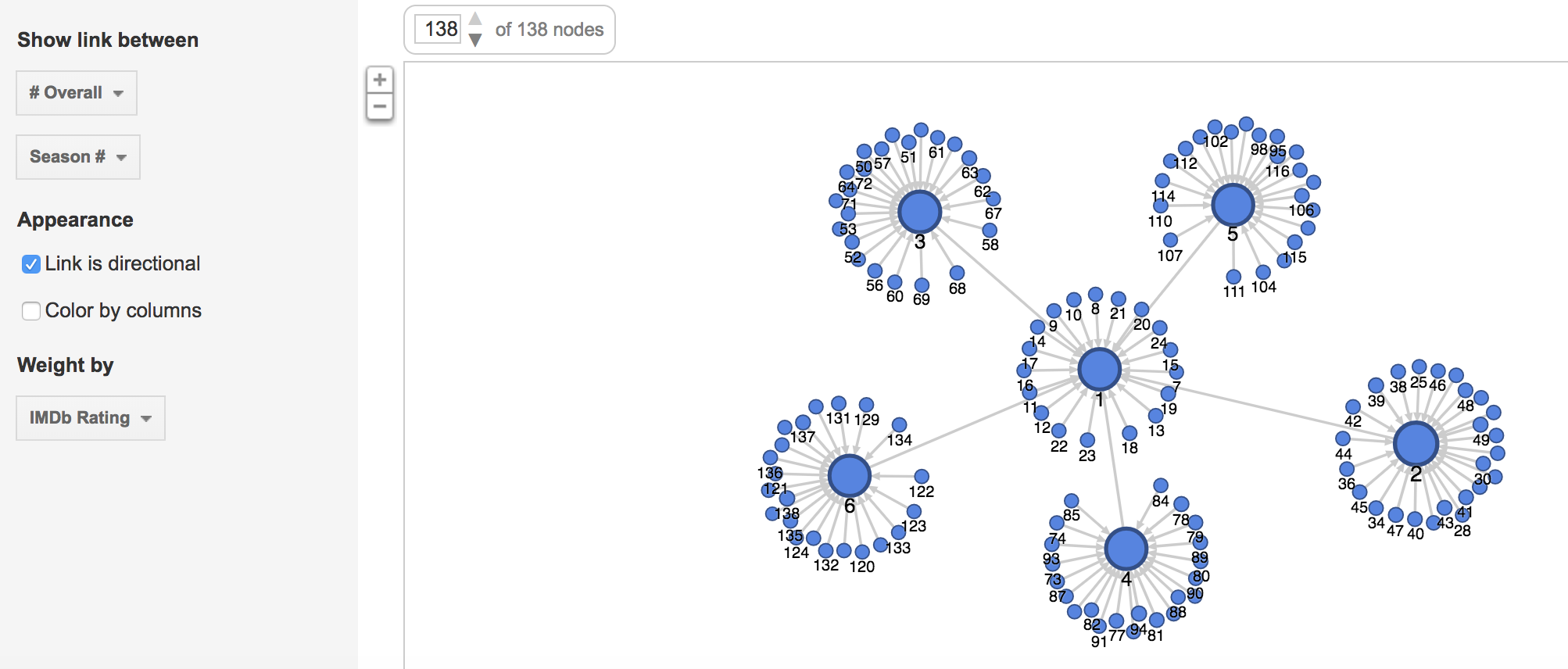
The following visualizations were created using the Graph function. The first shows the number of U.S. viewers to each episode, where the size of the node reflects the number of U.S. viewers.
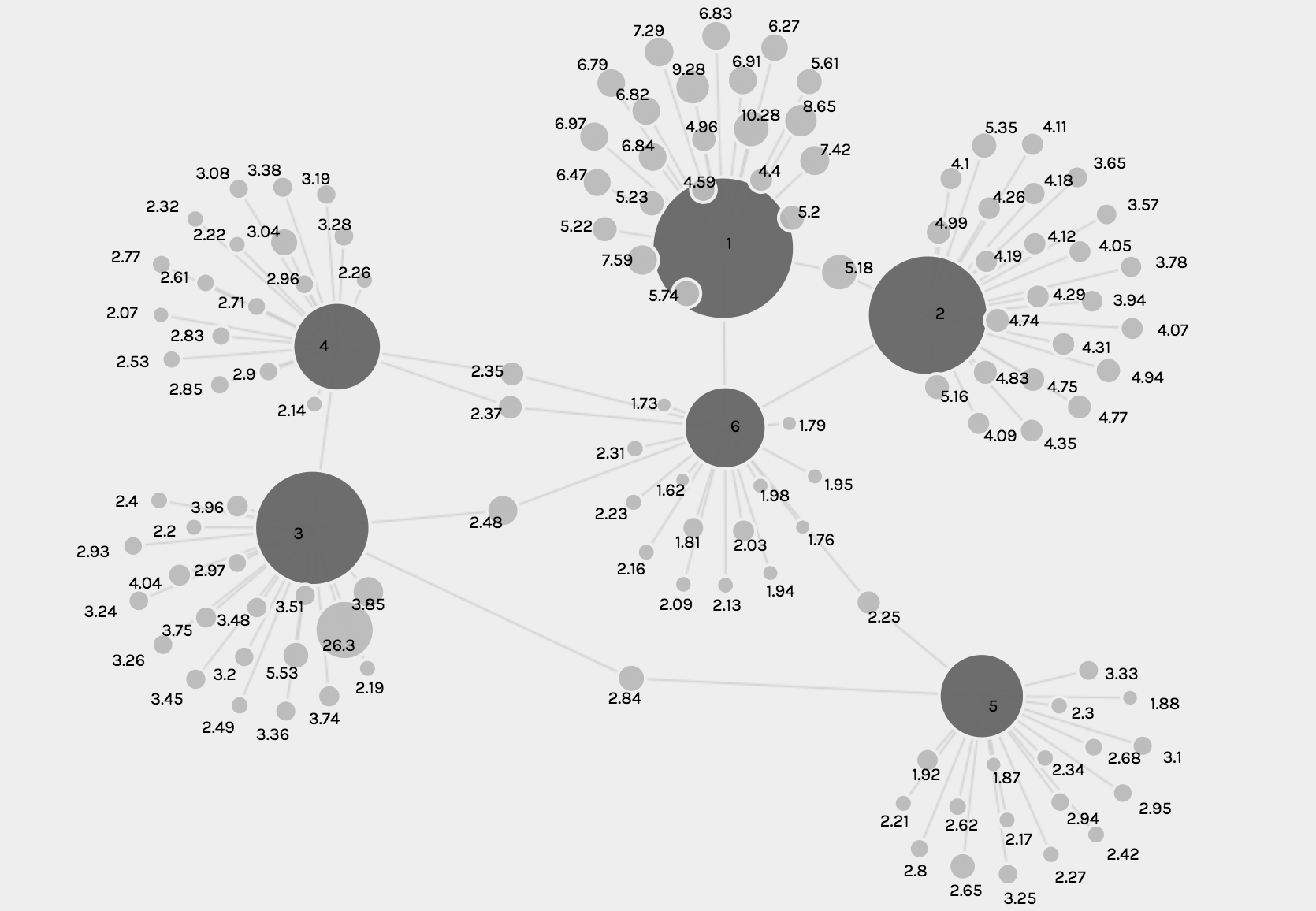
The second and third visualizations are the same, just with different zoom views, and these show the relationship between each episode and the IMBd rating for each episode, where the size of the node reflects the rating.


While the graph function creates detailed and intricate visualizations, from a user perspective, the visualizations are complex and difficult to read and comprehend, especially when they solely become static images.
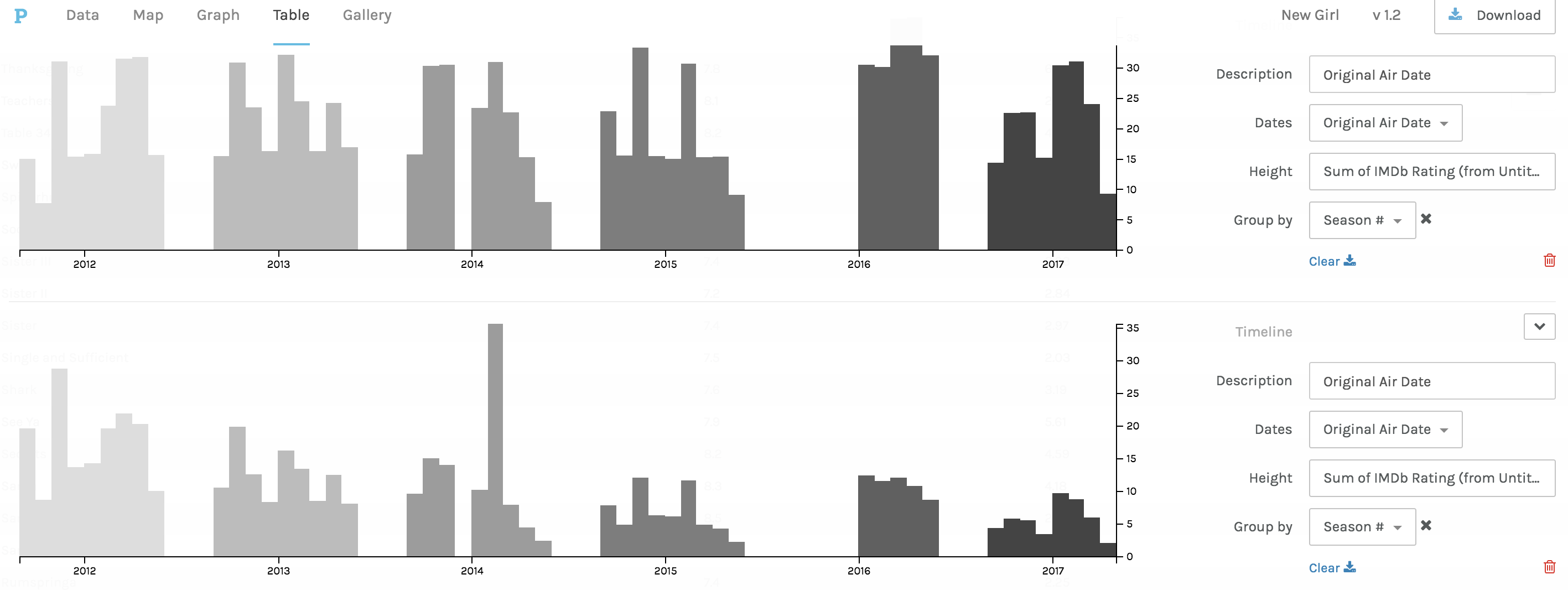
The third and fourth visualizations are bar graphs, which when Drucker explains the history she states, ““Bar charts came relatively late into the family of graphics, invented for accounting and statistical purposes, and thus pressed into service in the eighteenth century, with only rare exceptions beforehand. They depend on underlying statistical information that has been divided into discrete values before being mapped onto a bivariate graph.” (240) Both of these were used to clearly map out the changes in trends and numerical data from the original air date of the show to the present.
The first bar graph maps out the IMBd ratings over the air dates, and the second bar graph addresses the number of U.S. viewers over the air dates. While the charts are a clear visualization and one typically beneficial to numerical data, the Palladio platform for arranging these graphs was extremely difficult and had glitches.
Lastly, in Palladio, there was the Facet Feature, which was complex and difficult to comprehend exactly how and what it was doing. That being said, it created a list-like visual, which is beneficial to users in search of quick information.

In Google Fusion, similar visualizations to those in Palladio were created. The gallery and graph functions were very similar to Palladio, but differed in terms of user interface. The visualizations are below.
In comparison to Palladio, the gallery graphic in Google Fusion is not as aesthetically pleasing, however the graphing functions and graphics were much more user friendly and of equal level to the Palladio graphs.
While these visualizations are a convenient way to present information about New Girl and how trends in U.S. viewers and ratings have changed throughout the years, it is important to recognize that with all visualizations there is bias due to data used and aesthetic decisions, and as Drucker clearly states, “all data is capta, made, constructed, and produced, never given.” (249)
For this assignment, I used the Cushman Collection’s dataset. This dataset contains metadata of images taken by amateur photographer and Indiana University alumnus, Charles W. Cushman. Importing this data into Palladio and Google Fusion Tables reveals some interesting aspects.
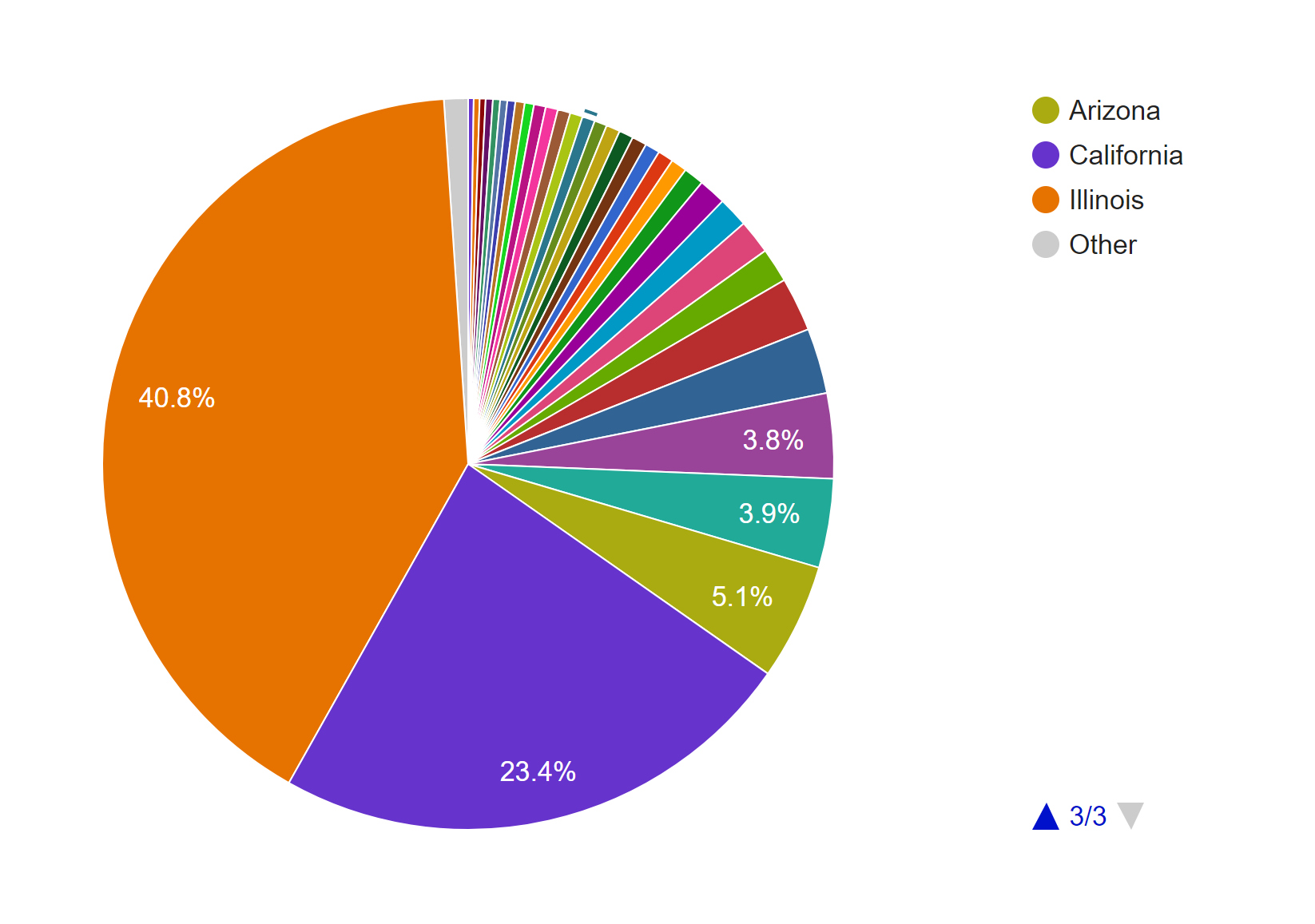
First, I tried mapping out the locations where the photos were taken. Looking at these identical maps from Palladio and Google Fusion Tables, we can infer that most of his photos were taken at Illinois and the West Coast.
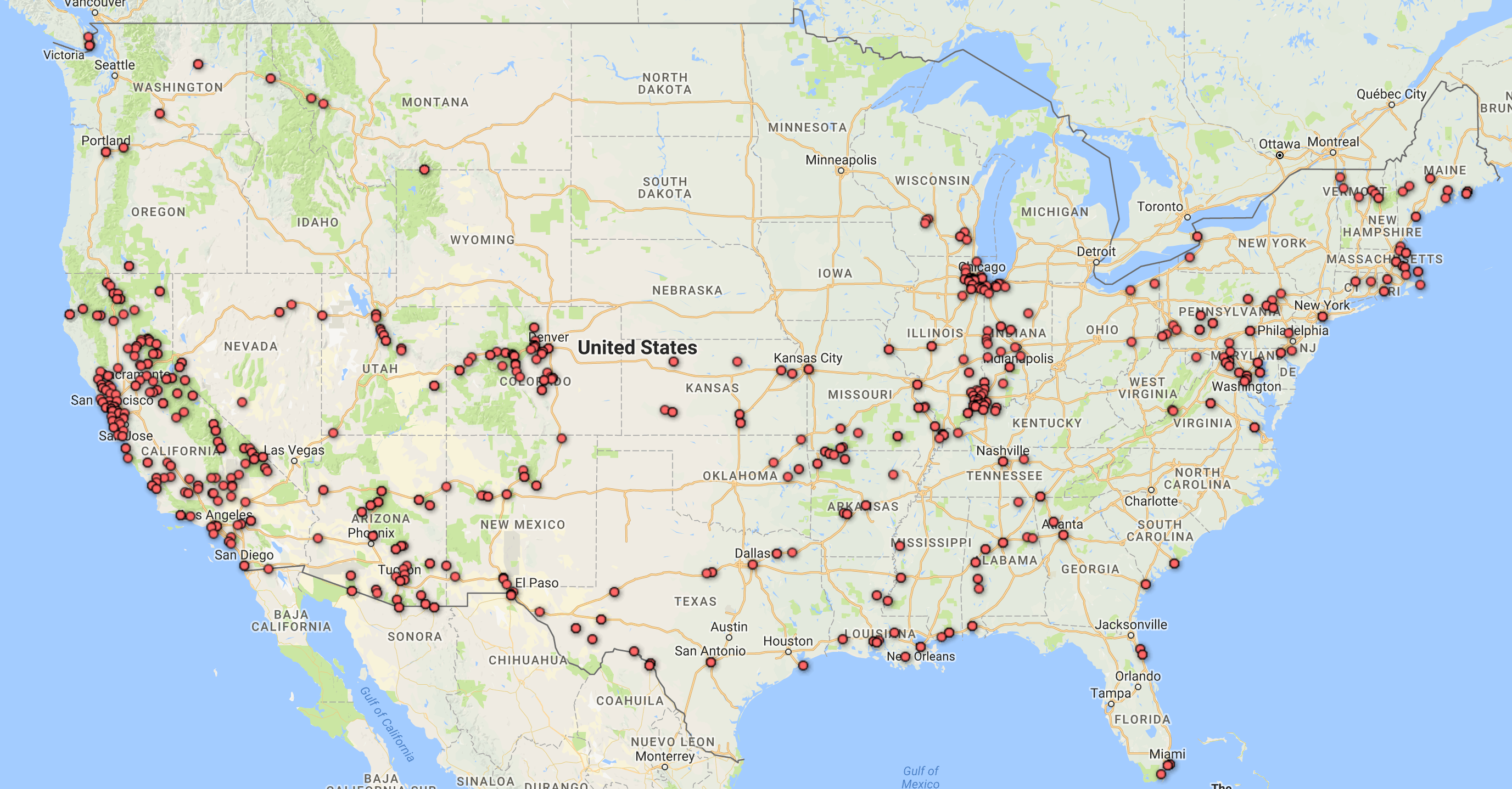
Adding a facet to the data in Palladio confirms our inference. Moreover, this facet also reveals that the photos from Illinois were mostly taken after 1940 and before 1952, while the photos from California were mostly taken after that period. A quick check at his biography provided by the Indiana University Archives reveals that he spent most of his life after college in Illinois and only moved to San Francisco in the 1950s. 

To further confirm this conjecture, I also made a pie chart in Google Fusion Tables.
The timeline tool from Palladio also tells us that his photos were not archived until the 1940s. After that period, however, they were archived not too long after they were taken. Although Palladio did not allow me to scale the x-axes of the two timelines to match each other, the general patterns seem to support my assumption.

 Timelines of photos by date taken (below) and date archived (above).
Timelines of photos by date taken (below) and date archived (above).The next thing I explored in this dataset is the genre of the photos. This information is provided in two columns, Genre 1 and Genre 2, in the CSV file. Since the Genre 2 column is sparsely filled out, I only considered the data from the Genre 1 column in my visualizations.
This pie chart from Google Fusion Tables shows that Cushman’s collection consists mostly of identification, landscape, architectural, and cityscape photographs.
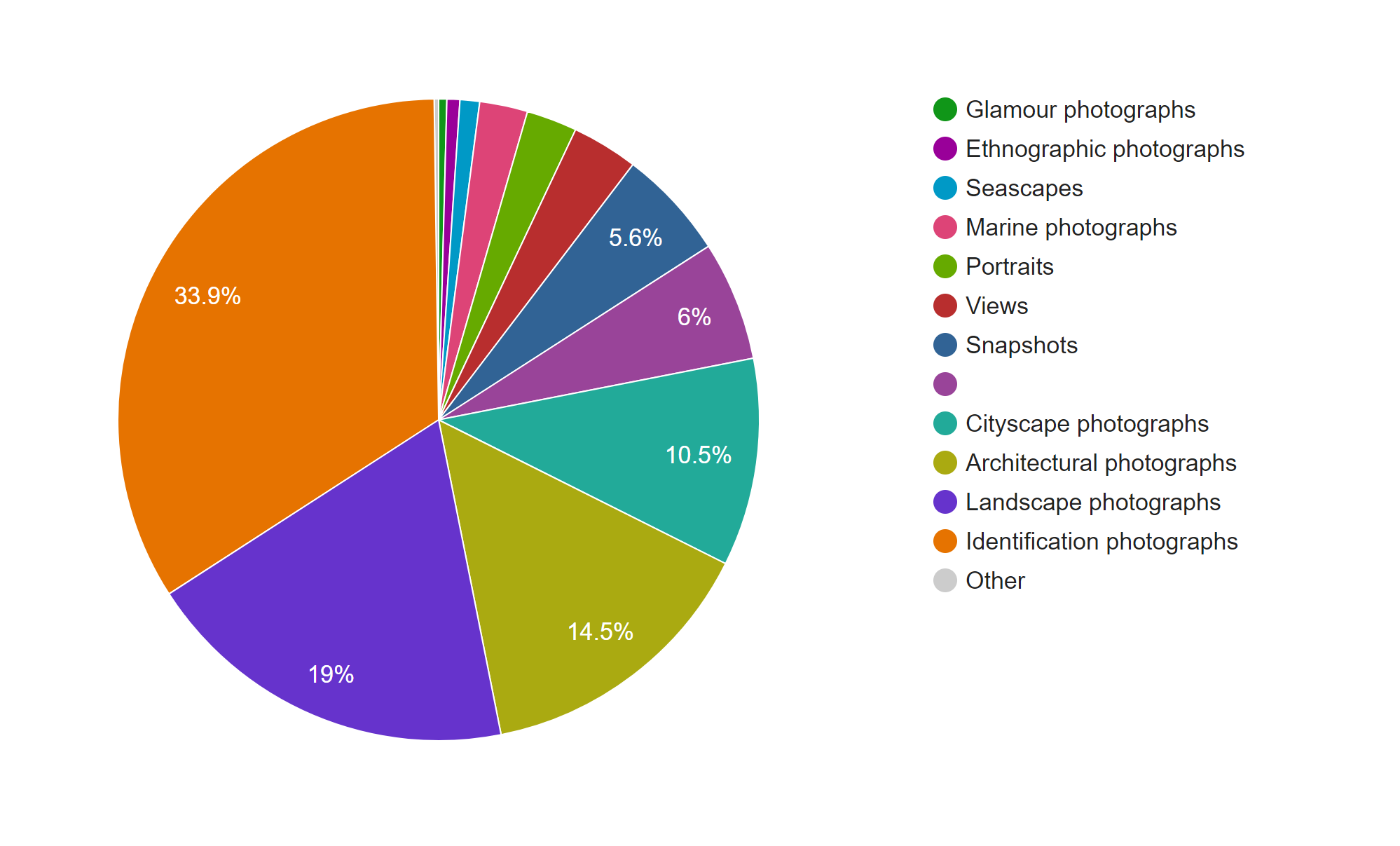
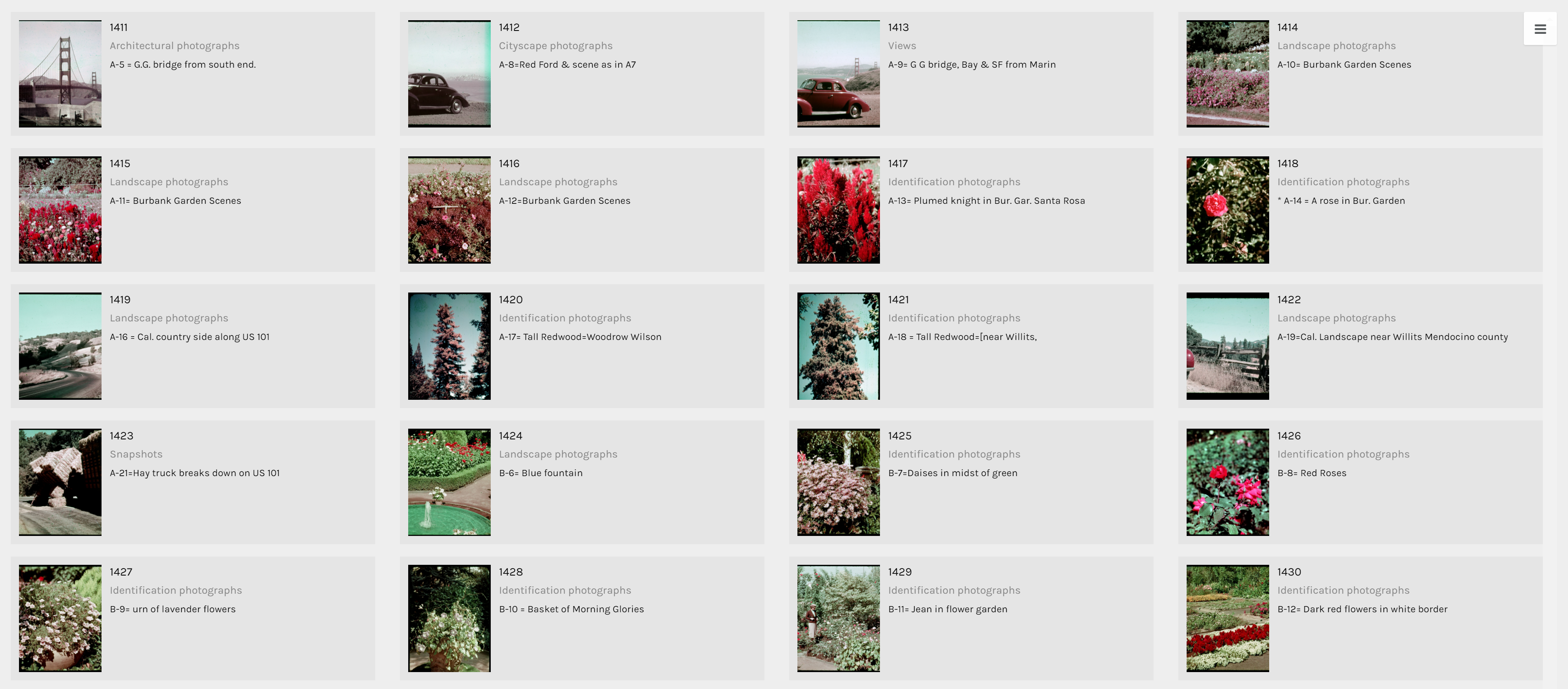
The term identification photograph as used in original dataset made me think that one third of this collection was portrait photographs that you can find on driver’s licenses and passports. However, switching to the Gallery view in Palladio, I realized they are actually identification photographs of species of plants.
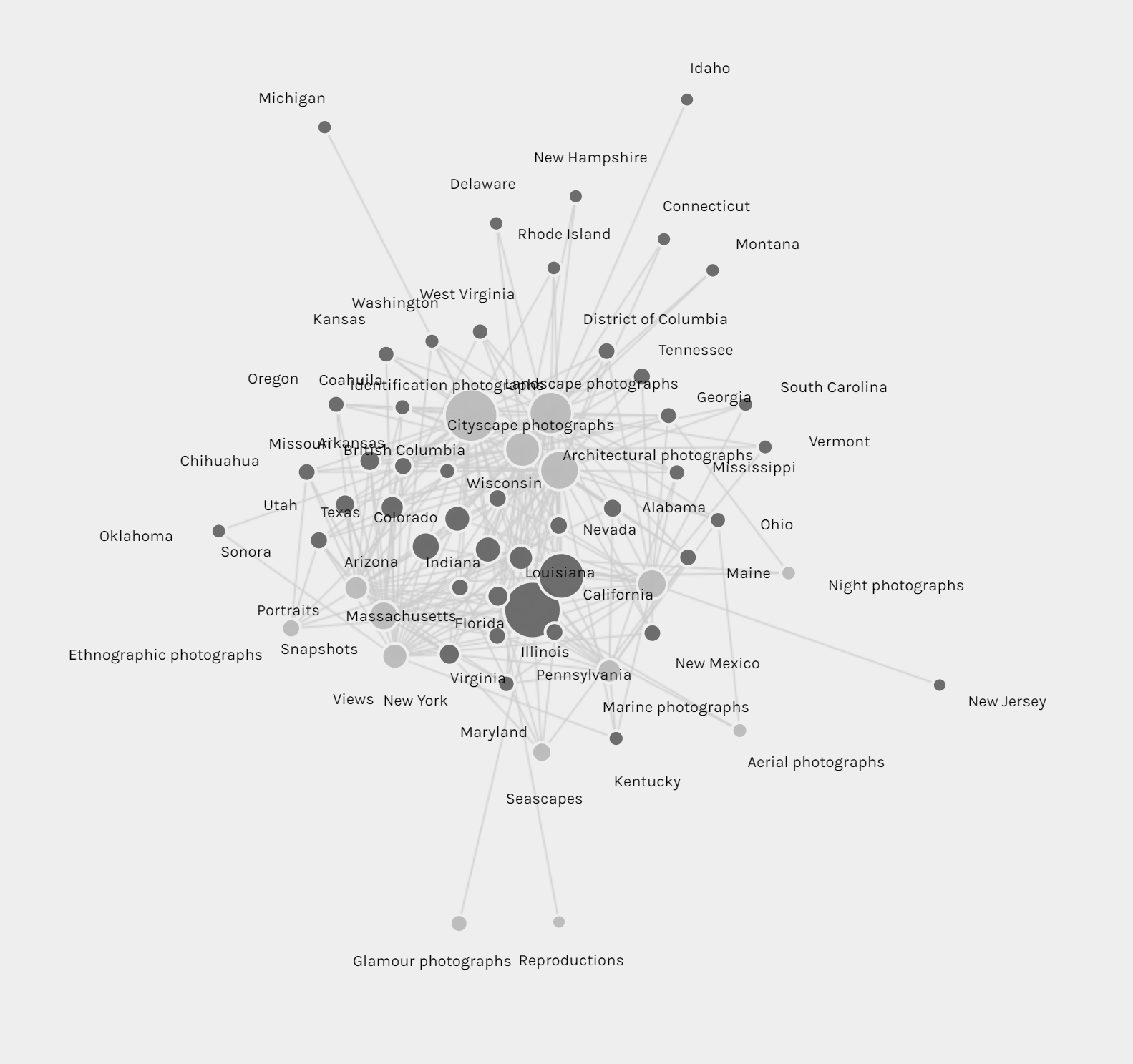
Another aspect of this dataset that I wanted to look into was whether the genre of photographs changed based on the state Cushman was staying. However, neither of the tools provides the option for stacked bar charts based on location. Thus, I tried creating network graphs with the state and the genre as my parameters. Although the resulting visualizations are quite nice to look at, they do not provide any helpful information and only vaguely reconfirms the assumptions provided by the previous visualizations that I made.
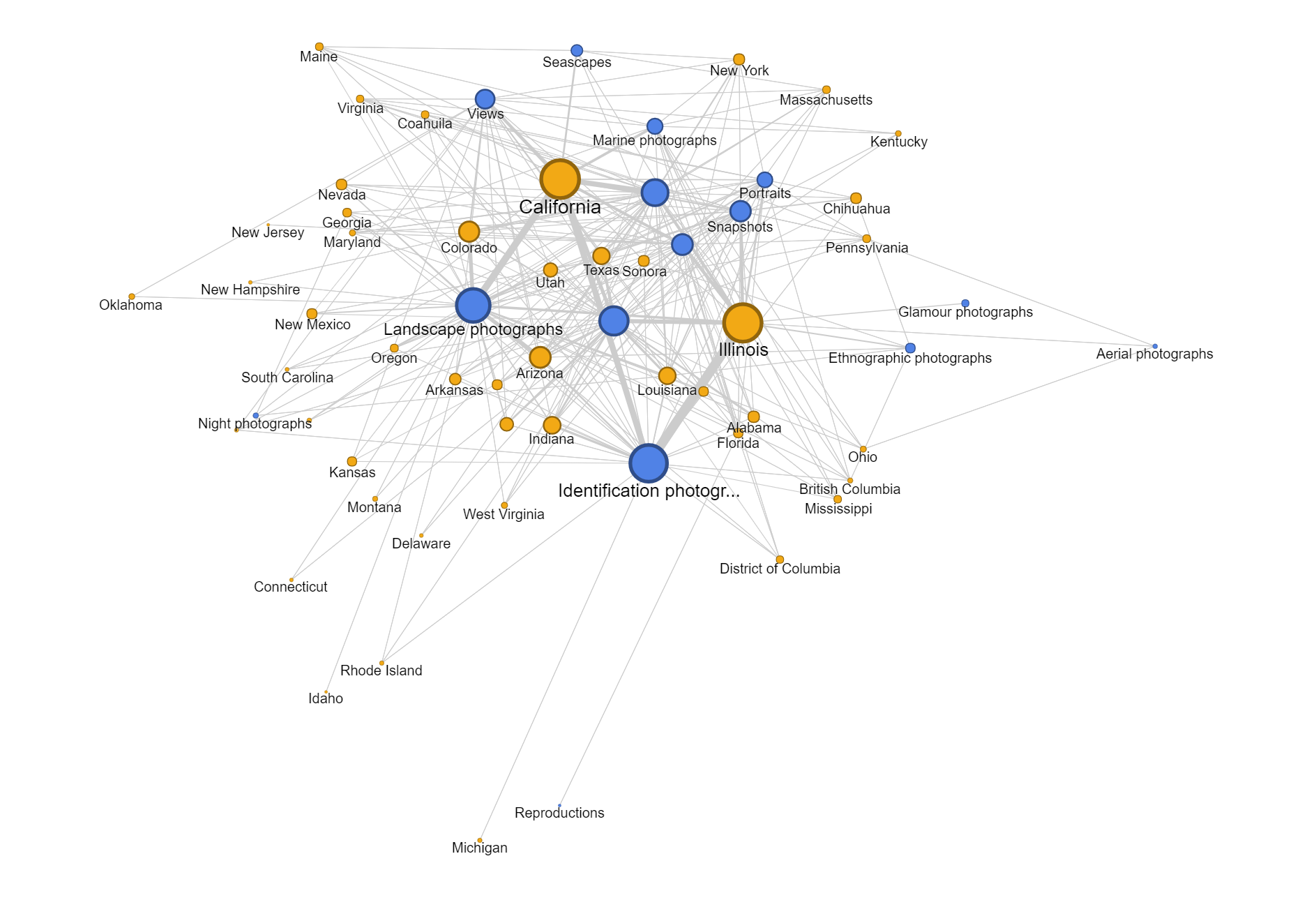
Since datasets, particularly this one, are usually multi-dimensional, I think that these kinds of visualizations can only present a certain aspect of the data at a time. In other words, they are partial representations rather than the whole image of the data itself. As Drucker mentioned, since these methods of visualizing information come from the natural sciences, they impose certain biases on the visualizations themselves. For example, we know from the dataset that Cushman took a lot of identification photographs. However, by counting the number of photos in each genre, we also strip these photos of it aesthetic and sentimental values. For instance, we do not know which photos were the defining moments in his photographic style or which were the ones that meant the most to him emotionally. Or just simply by categorizing the photos as identification photographs without providing the thumbnail images can give the viewers a wrong impression of the kind of photographer he was.
Nevertheless, it does not mean that these kinds of visualization do not generate new knowledge. Nowadays, data is being generated at an unprecedented rate. Since human’s computational capacity is limited and this data is mostly digital-born, computer-generated visualizations provide an efficient way of discovering things about humanities. For example, the maps that I created infer that Cushman lived and worked in Illinois and California for most of his life, which was mentioned by the Indiana University Archives. On the other hand, by arranging his work on a timeline, we can also the period where he moved to those states.
News about Trump in the White House’s Official Website in 2018
I gathered all news posted on the White House’s official website, and have created a table of meta data of those news, which include file names, date, word count, category, issue and location. For now, my main focus is on the issue of those news, so that we can know what kind of issues the president has been paying attention to.
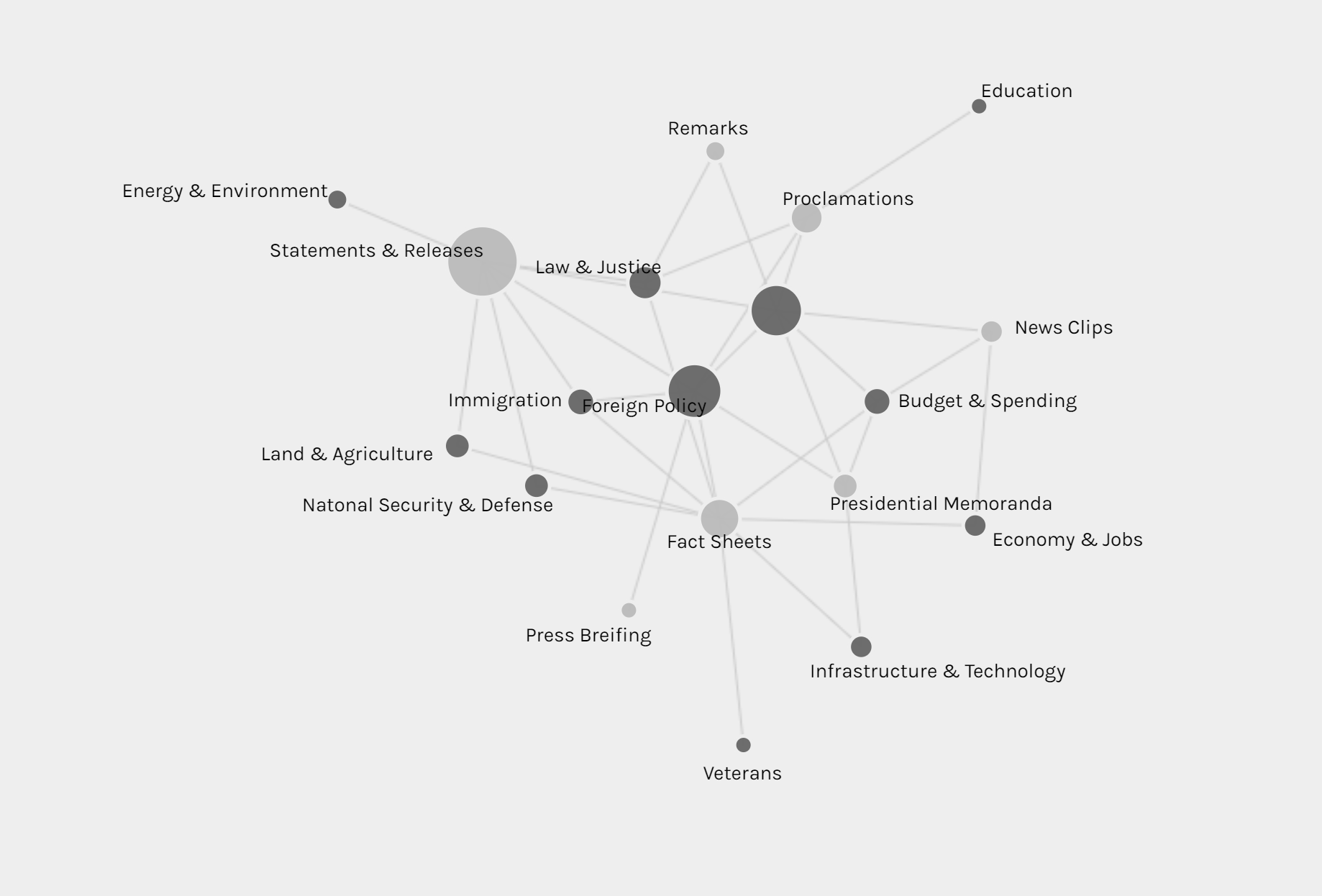
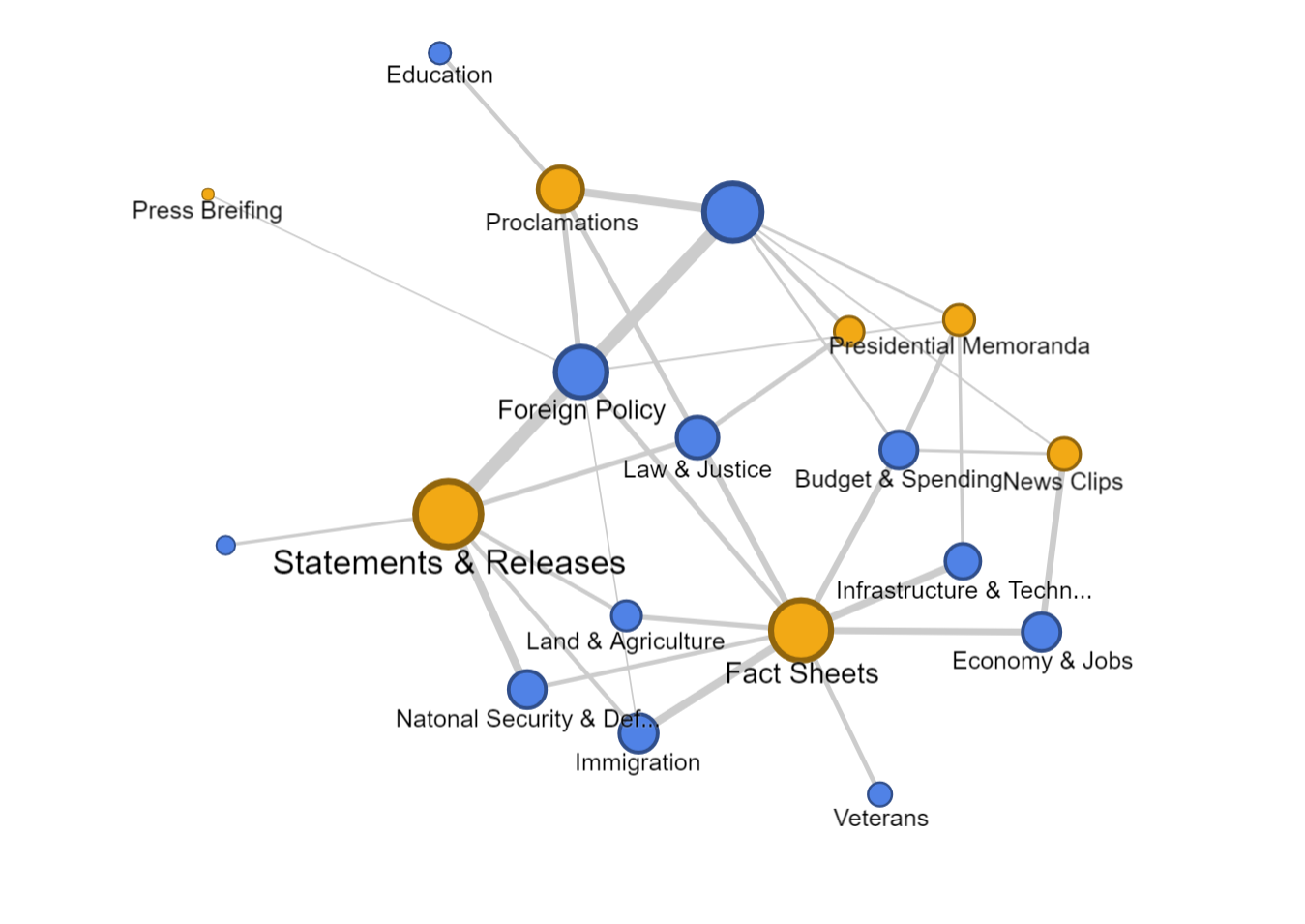
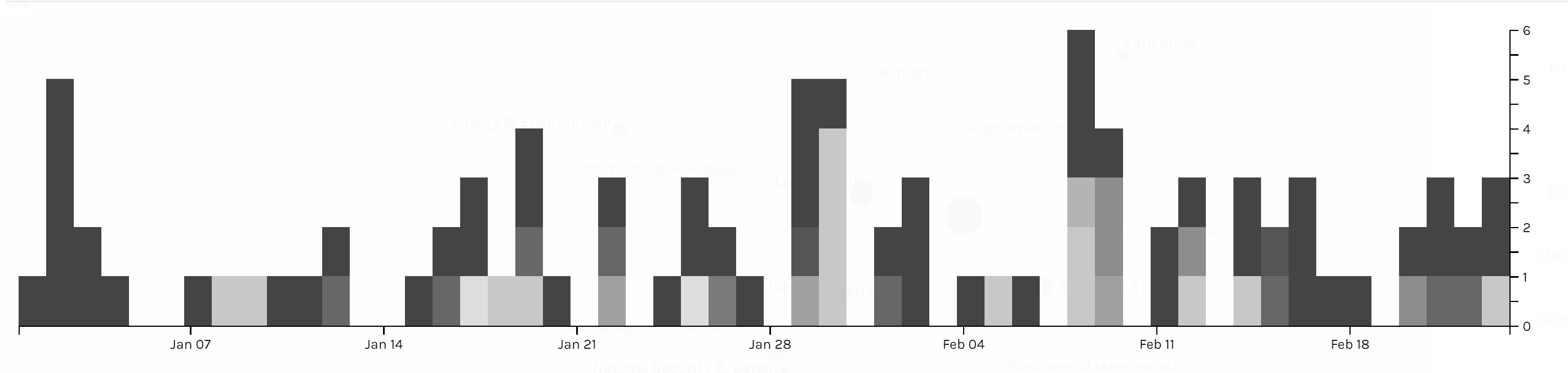
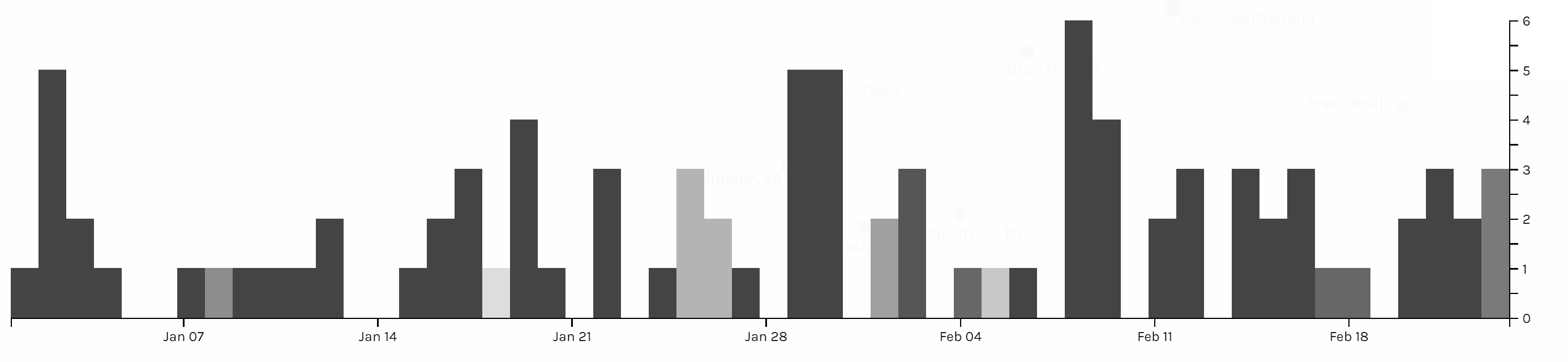
The first graph is produced by Palladio and Google Fusion, with category as source and issue as target. Intuitively, the network relationship for category and issue shouldn’t have too much significant meaning. But from the network graph below, we can interpret some information by adding the size of node as a feature. Most news is in the category of statements & releases and about foreign policy. Statements & releases connected to most kinds of issues, only education, economy & jobs and infrastructure & technology are posted by other category of articles. So we can know that dealing with different issues, the White House might use different form of articles. Compared to the graph produced by Google Fusion, I think Palladio should learn from Google fusion to change the color for different kinds of nodes. Although nodes can be highlighted, the difference of color is not significant enough. Another advantage of using Google Fusion’s network graph is that it shows the weight of relations between nodes with the thickness of lines. Palladio is also not flexible enough to control the number of nodes in the graph; in this project, the number of category is in a rather small number, so the graph is still clear for user to look at and read about details, but when there are too many nodes and users only want to learn nodes with highest weights, then the feature like limitation on the number of nodes in Google Fusion would be needed.
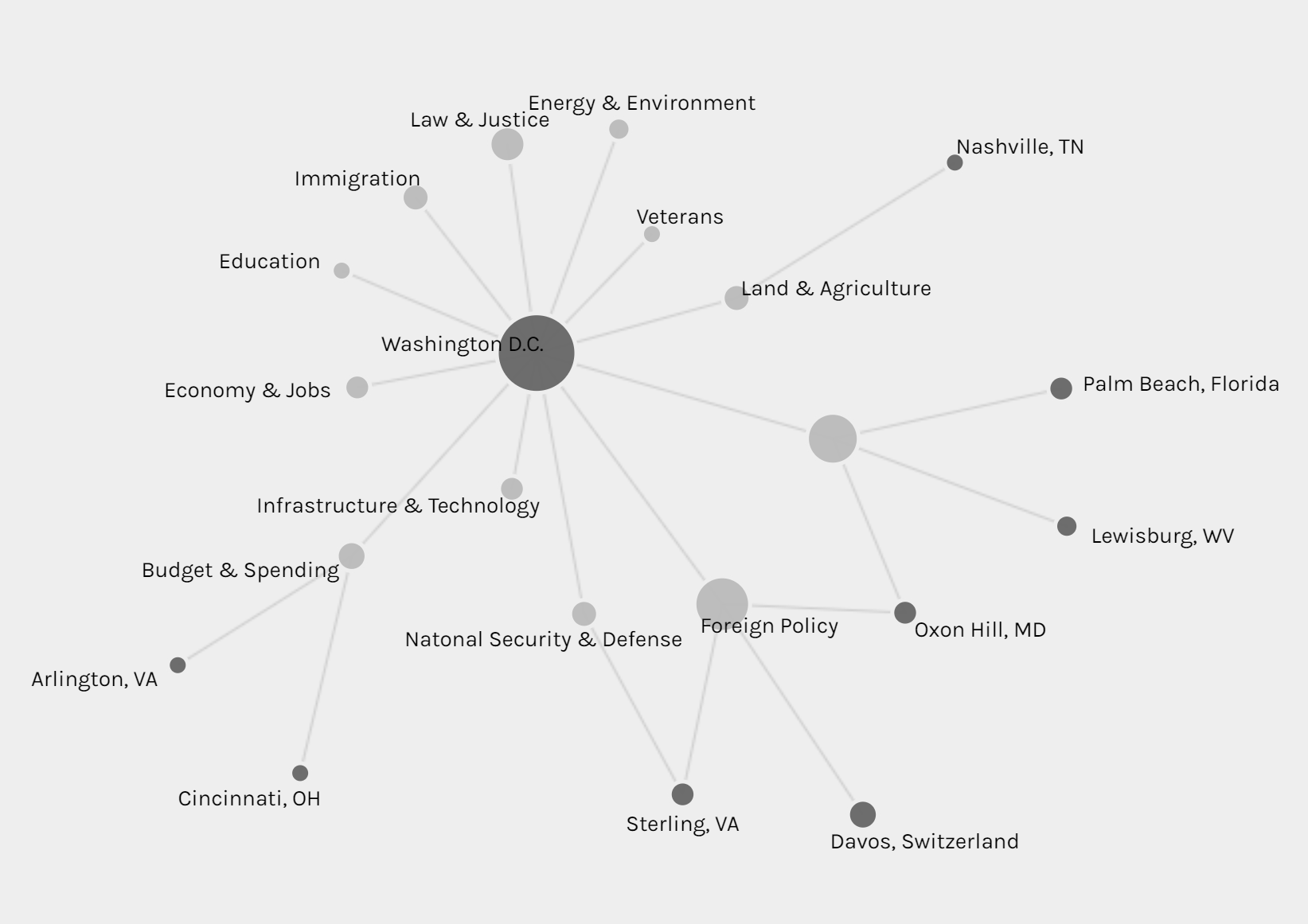
The second graph is also a network graph with location as source and issue as target. From this graph, we can interpret more information than the last one. Most news are posted when Trump is at Washington D.C. (most time in cabinet room, oval office or south lawn) and most issues are also in Washington D.C.. News posted outside are usually highly related with the issue happened at the date of that news. For example, the news posted on January 8th was about the rural America’s living condition and on that day, Trump visited Nashville, TN and gave remarks at the American Farm Bureau Federations Annual Convention. Another example, when Trump was attending World Economic Forum in Davos, Switzerland, news in that period is about Foreign Policy.
Those three graphs are timelines for issue, category and location. I don’t see any pattern on the category and issue of articles. And due to the timeline, we can see in the first two month of 2018 Trump didn’t spend too much time on business trip. In my project, timeline is not very helpful for users to interpret data, but I think the combination of bar graph and timeline can be a powerful tool for analyzing data like stories or events. The frequency of words or persons in time line can help users to learn about the focus of topic of an event of the clue in a story.
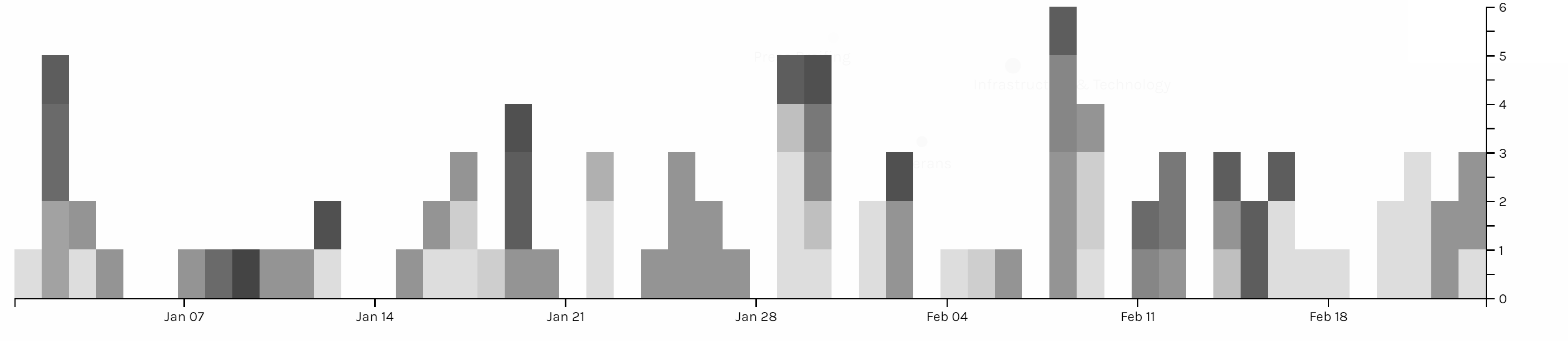
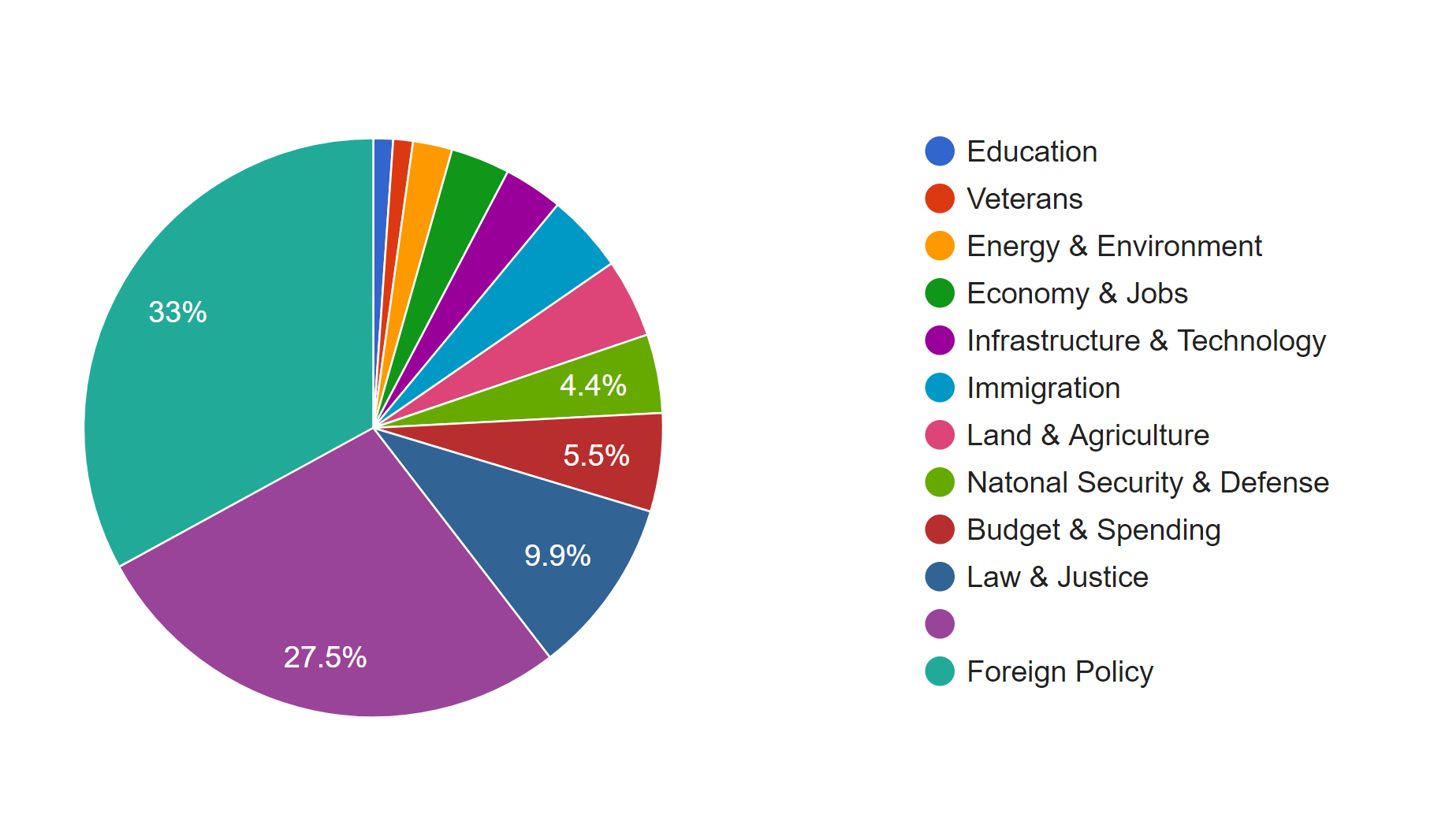
I also produced two pie charts for issue. Foreign policy takes the largest area and is the main focus of Trump during the beginning of this year. And we can see there is 27.5% of news is not classified with an issue by the White House. So I guess that’s what Drucker mentioned about misinformation; because when a large part of information might be omitted, ignored or untouched, the visualization of data may present imprecise data and mislead viewers. Take this pie chart for example, what if the part without being categorized is about law & justice, then in that situation, law & justice could also be a main focus of the president Trump. And that’s why although I have word count in my metadata, I choose not to use it. Because the number of words in a piece of news might represent the importance of it and it might not. Maybe it just needs more words to explain something. Similarly, what we have done in previous assignments, that we usually use the frequency of certain words to interpret data, might also be a misinformation, because maybe certain terms can be told only in a unique word, like nuclear, but terms like freedom can be also be told in liberty, essence, liberfree, or free will, then judging on the focus of topic with the frequency of words would be misleading.
Thinking more deeply, although the news posted by the White House’s official website is about foreign policy, what if many news related to other issues are not provided by the White House with news? Then the main focus of the president might not be foreign policy, and may be it is the image of the president the White House wants to present to people. Then visualization of our data will be misinformation and what Drucker tried to tell makes a lot of sense.
Therefore, I think, to prevent misinformation, we need our data to be comprehensive and multi-dimensional. Comprehensiveness can avoid omitting important parts of data, so the graph could be statistically precise; in this project, news which is not classified is a lack of comprehensiveness. Multi-dimension can avoid ignoring important perspectives or points of view to the data; in this project, we only have news from the White House’s official website, so the our data only represents the White House’s point of view on the president Trump.