Kyle Adams
Humanities 270 – Faull
May 2, 2018
Final Blog Post: Final Project Process
As you have heard over the course of the semester, my final project involves an investigation of responses to the 2011 Penn State Child Abuse Scandal. What I have grown particularly interested in is using my newly acquired digital humanities competencies to drill down into the factors that played a role in conditioning discourse surrounding Sandusky and Penn State University’s crimes. For the final project, I chose to expand upon some of the original work I did this semester (Assignment 2) by utilizing new analytical tools (IBM Watson Natural Language Understanding tool for sentiment calculations) and looking at novel features that impacted responses to the scandal (for example, looking at response platform by adding fifty tweets to my corpus). My ultimate goal in working with this corpus and visualizing the impact time, geography, author gender, and response platform can have on discourse was outlined well in one of our early readings this semester, “…DH scholars who have successfully used visualization in their analyses … argue for the new hermeneutic of digital visualization, the way in which their visualizations produce both new knowledge and also invite ambiguity, the traditional province of humanistic critical thinking” (Faull 2). Upon completing my final project using Palladio and the WordPress platform, I believe I have accomplished each of these goals, as my visualizations not only clearly demonstrate that author gender, time, and response platform played some role in conditioning response sentiment and message, but also open the door for humanistic inquiry focused on the social dynamics and cultural mechanisms that allowed them to do so (show that there was an impact and welcome investigation into why these specific factors played a role).
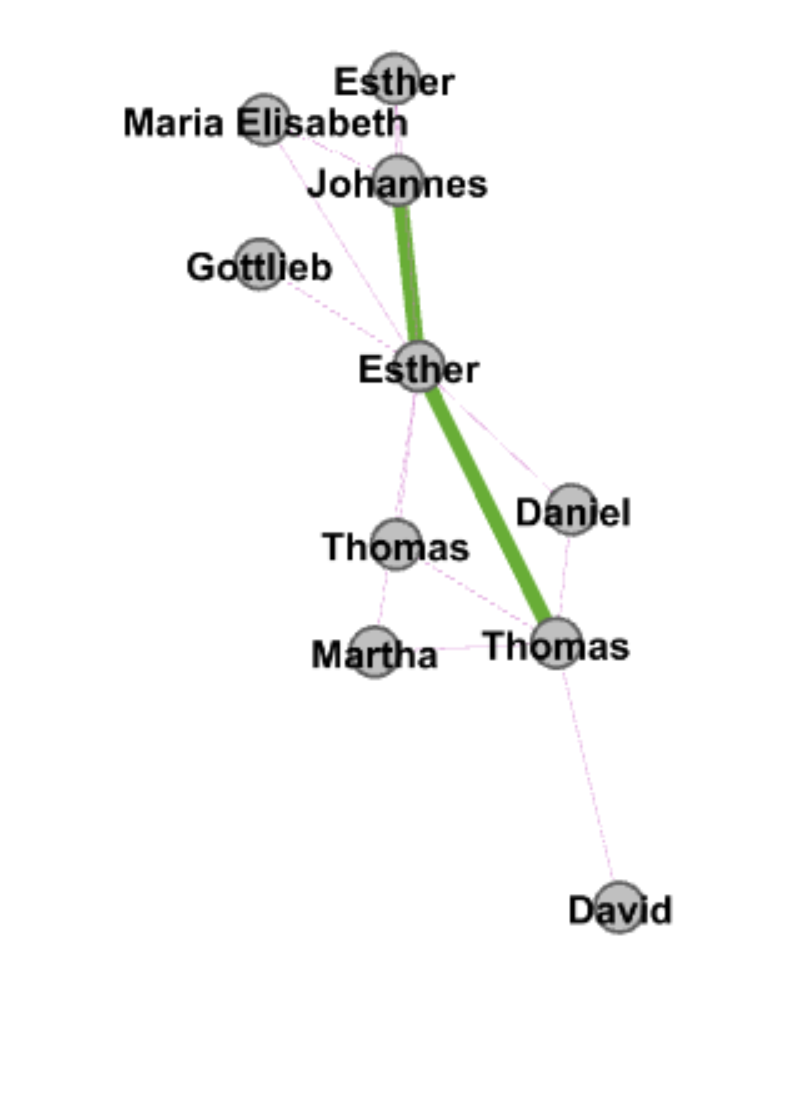
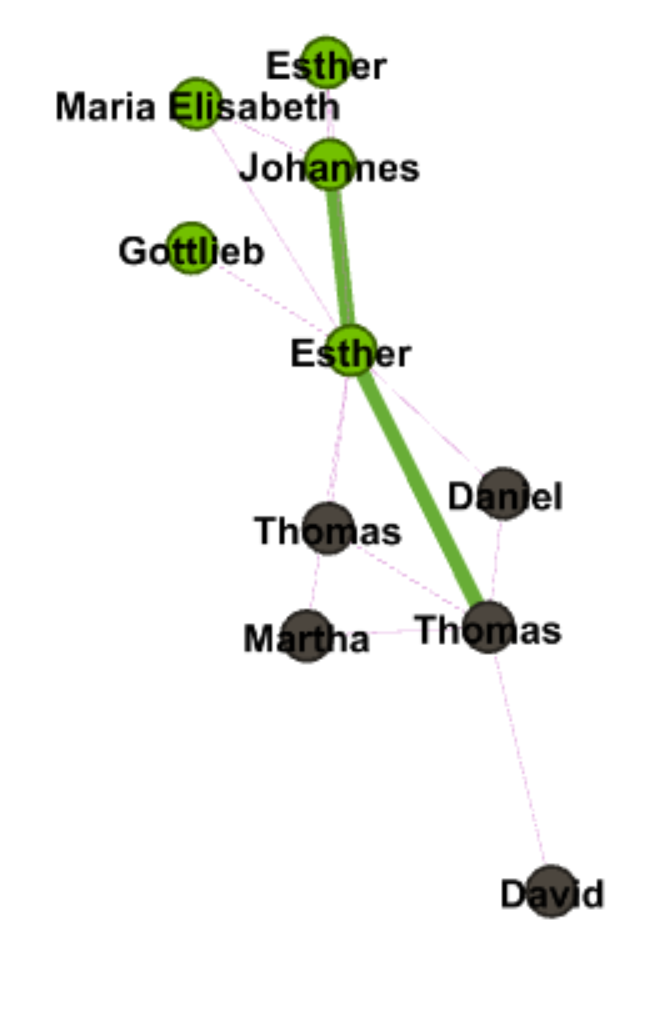
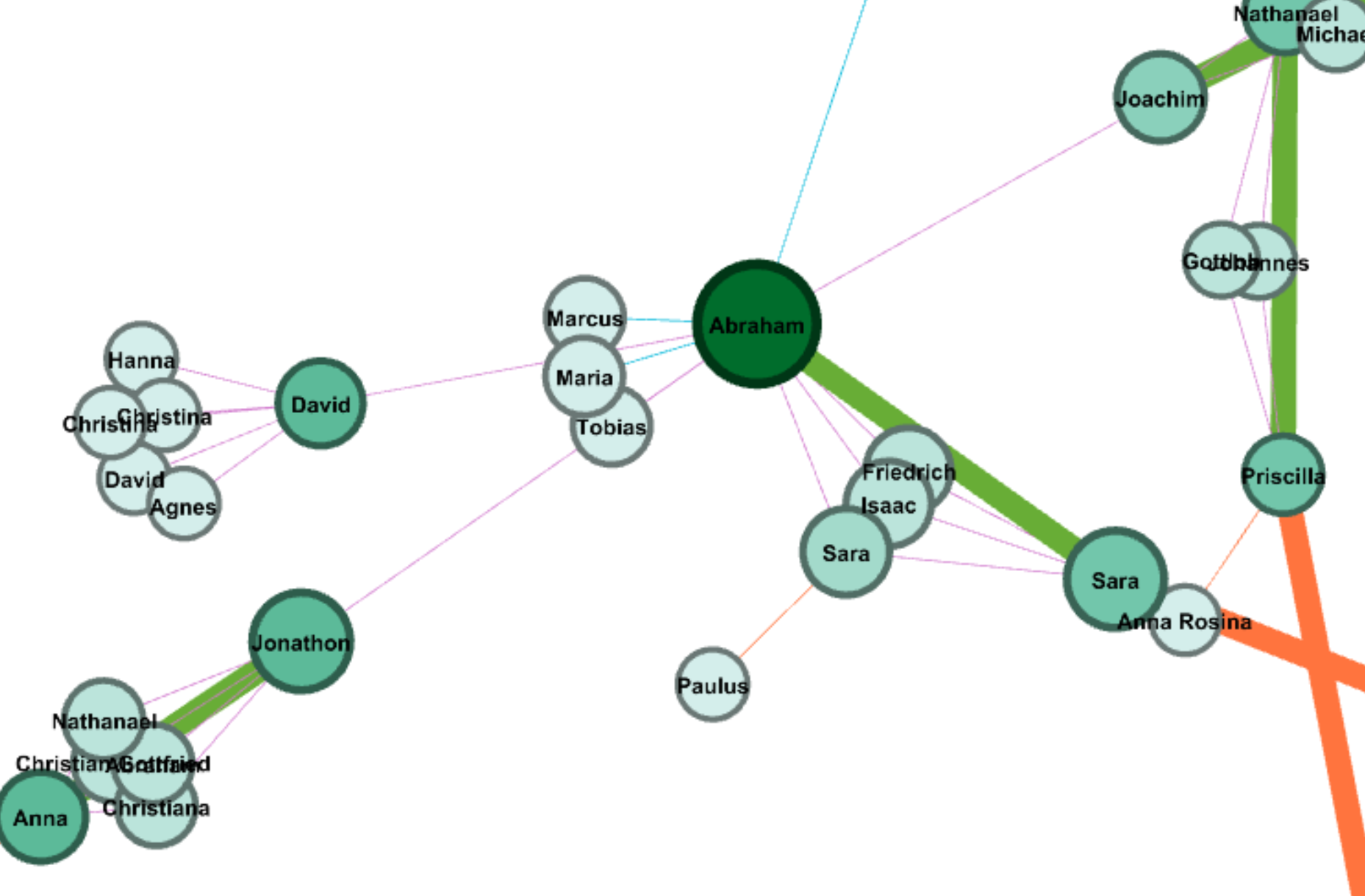
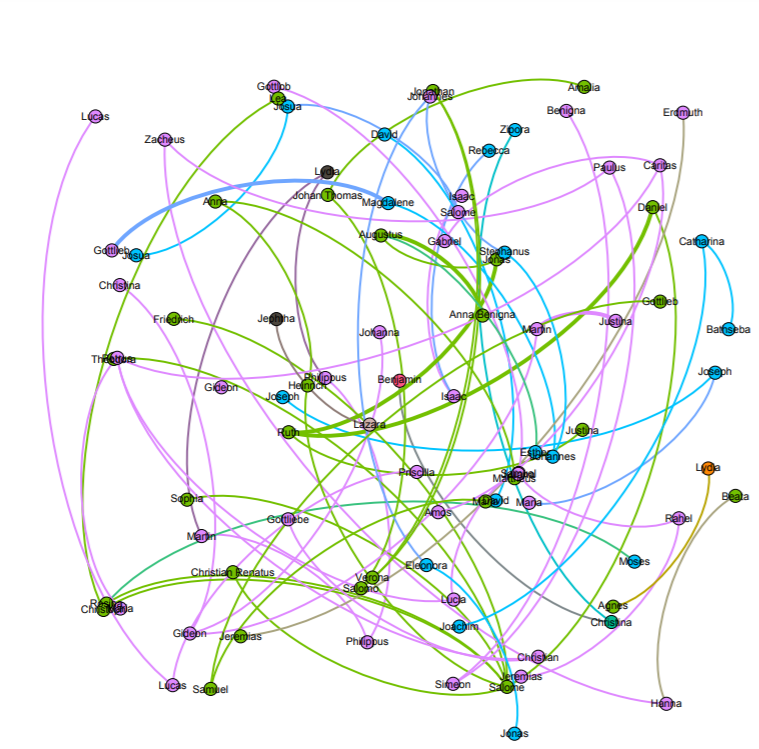
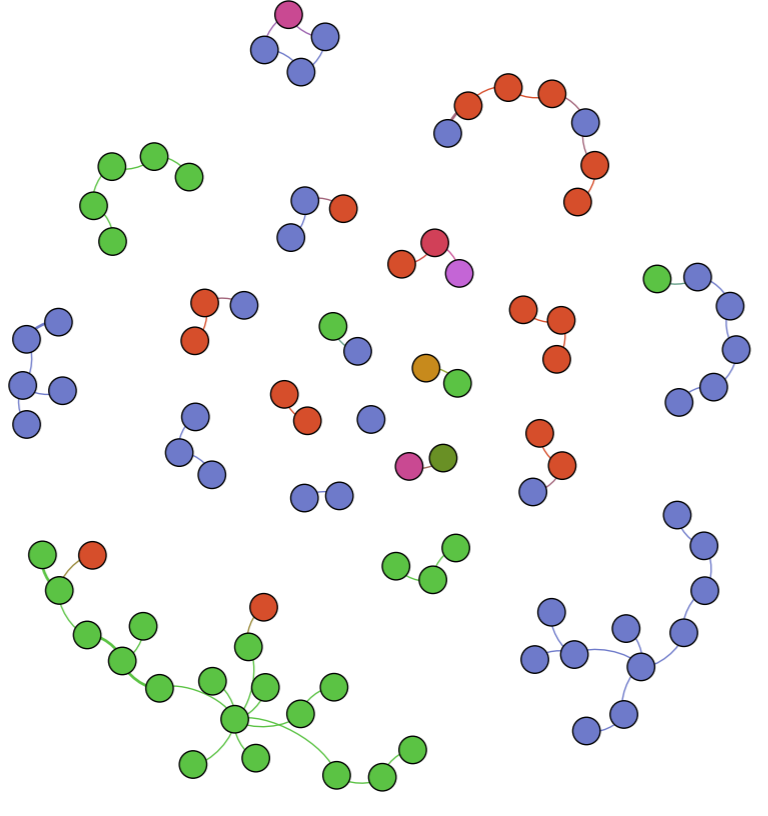
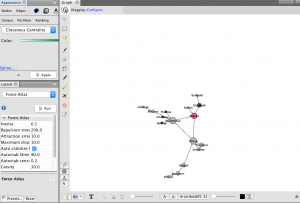
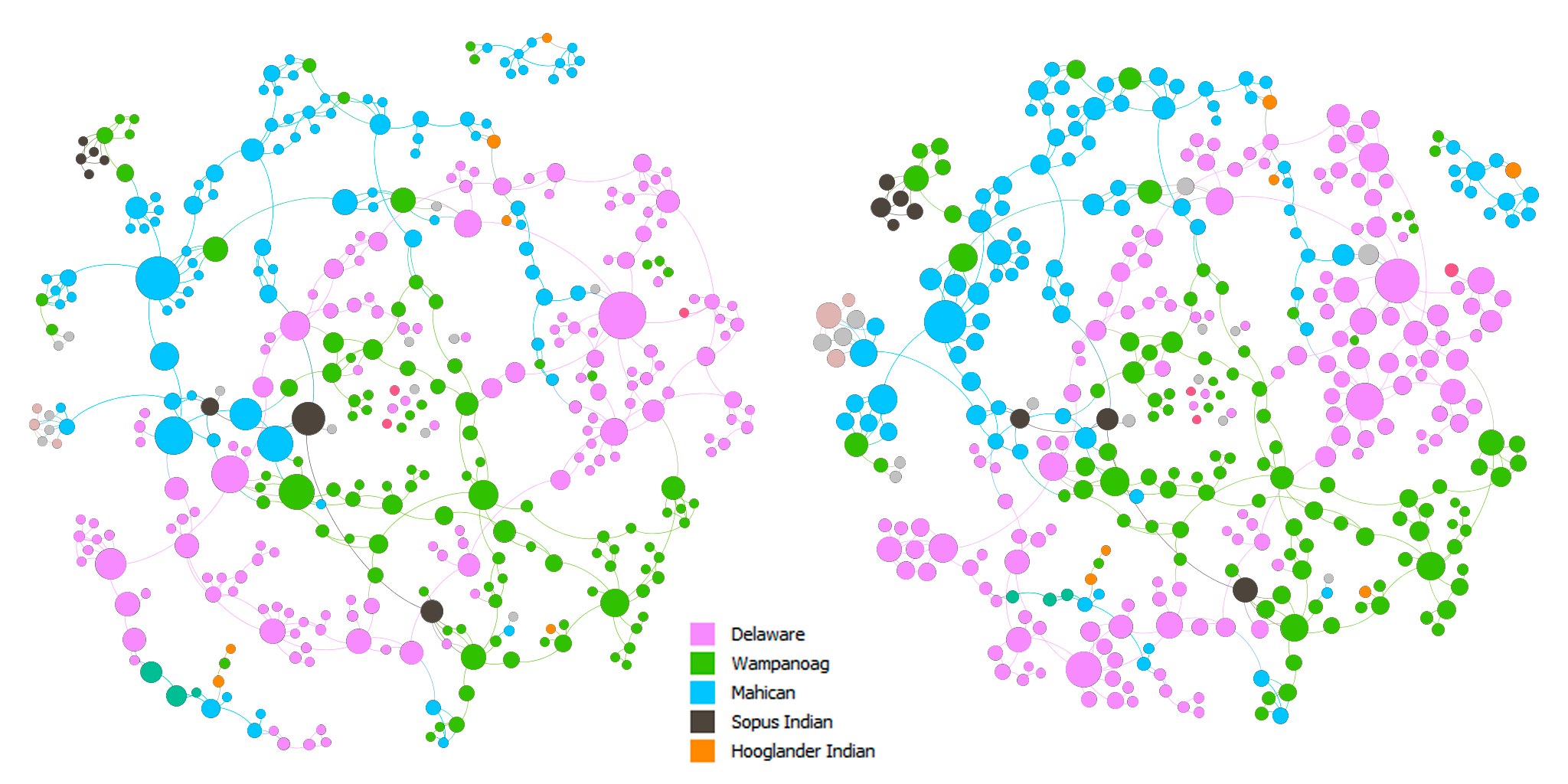
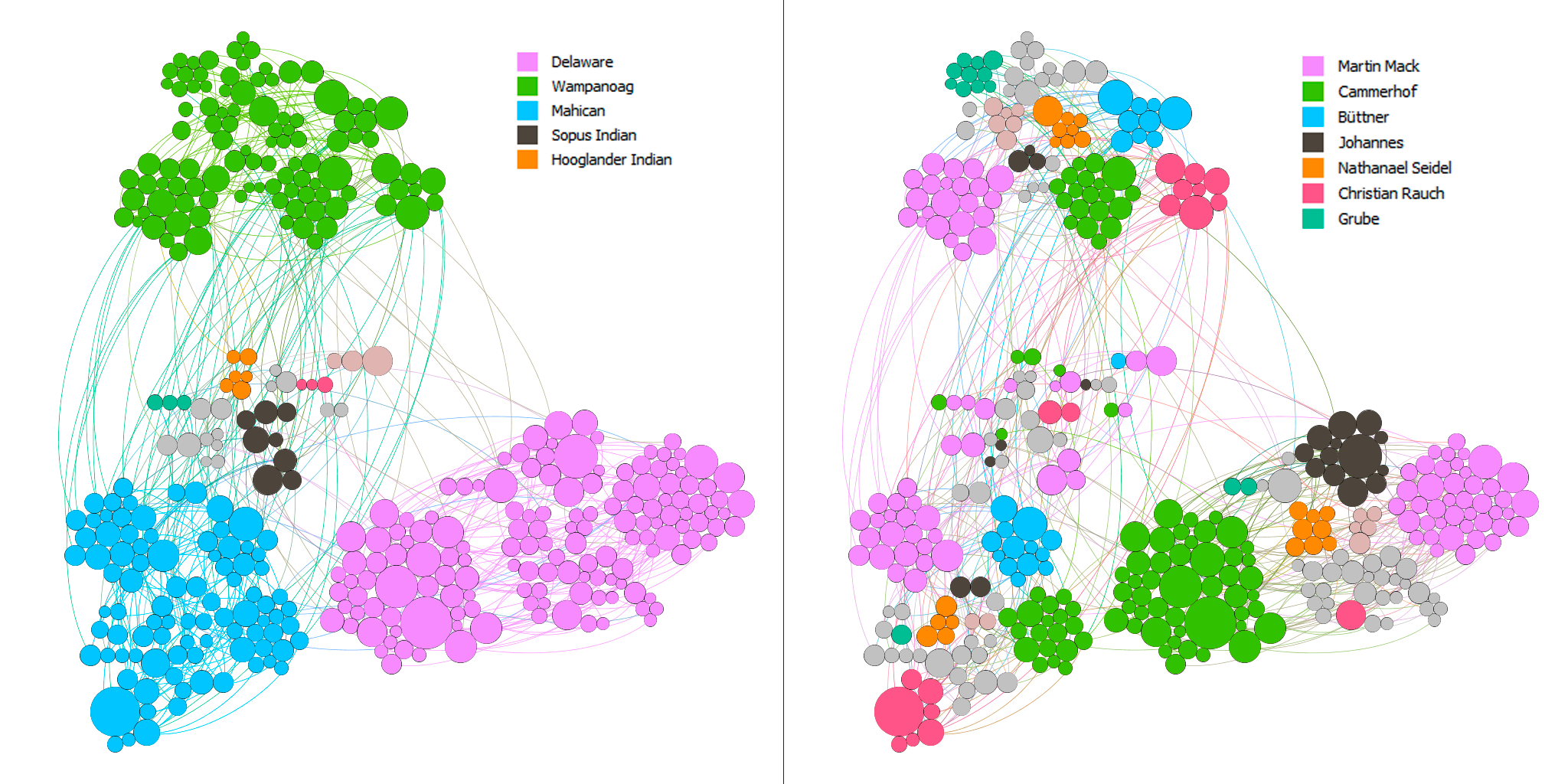
Throughout the production process for my final project, I ran into several challenges in working with the Stanford Design + Humanities Lab’s Palladio platform. Over the course of the semester, I have found that Palladio is a fantastic tool for research like mine, as it gives individuals the power to visualize many dimensions of a corpus. In my case, this prevented me from overwhelming the interpretive capacities of audiences by attempting to visualize the multiple dimensions I was interested in on a single plain. However, the versatility of Palladio did not entirely prohibit me from suffering from a common problem identified by Elijah Meeks: “Regardless, the first step is awareness of what a tool or method is dong and how it will inflect your research. I’m concerned that humanities scholars show a willingness to defer to tools…” (Meeks 2). In my case, this problem came about when I had to reformat my metadata in order to get the narrative I was trying to visualize to “fit” the software. Initially, my metadata was structured in such a way that each element of the corpus (article or tweet) had multiple “Key Themes” assigned to it in a singular row. However, because this did not work with Palladio’s “Graph” feature (as I could only represent one theme per article/tweet, therefore leaving many subsidiary themes absent from my network), I was required to duplicate entries in my metadata to accommodate the fact that I wanted to visualize more than just one “Key Theme” per article/tweet (so I went from 105 elements to over 300). Unfortunately, my “deferring” to the tool I was using caused problems when I attempted to visualize other dimensions (for example, “Gallery” or “Map”) as my duplicate entries led to redundant material in my map visualizations and catalog of corpus elements. The only solution I was able to come up with for this problem (inability to reconcile my desire to portray multiple themes and have a logical gallery and map view) was to separate my work into two separate Palladio “artifacts.” One of these would be used to generate visualizations in the “Graph” tab (networks, timelines, and tables) and the other would be used for “Gallery” and “Map” views.
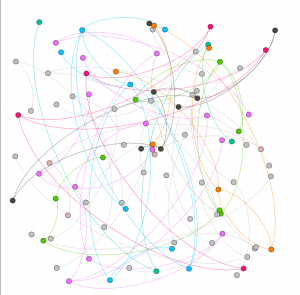
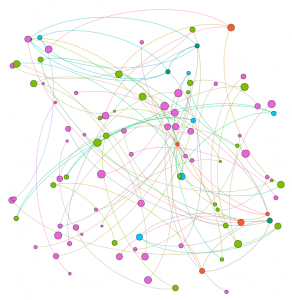
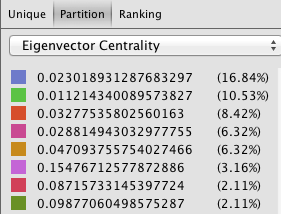
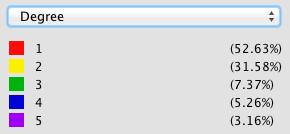
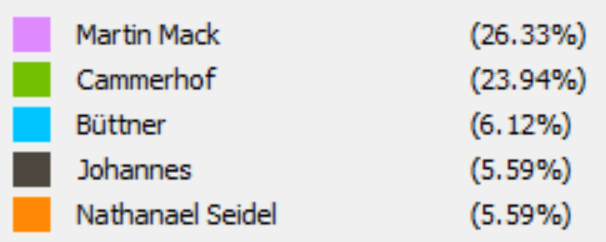
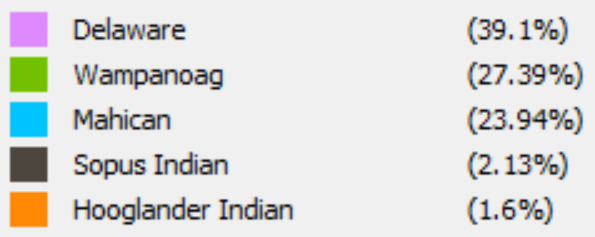
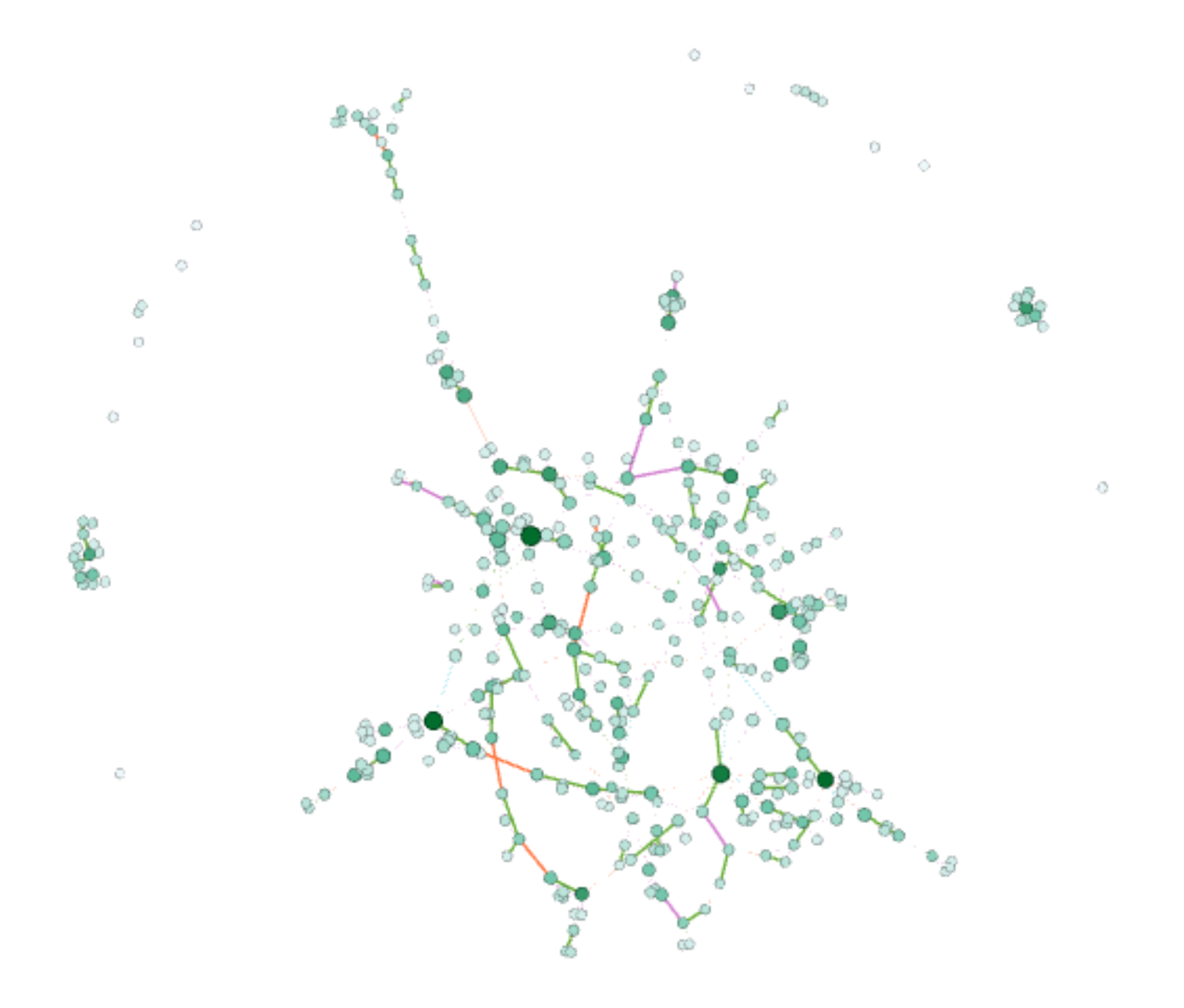
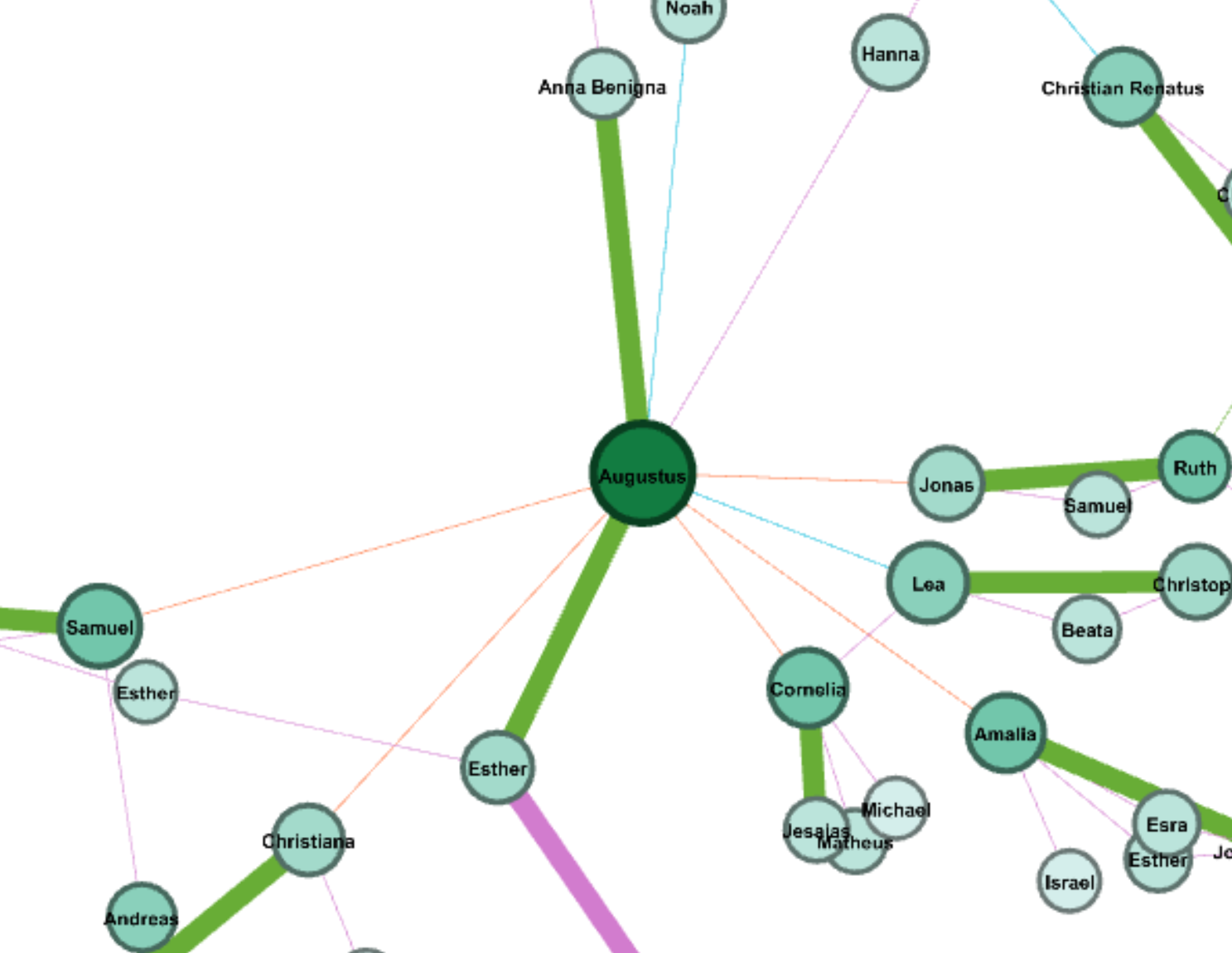
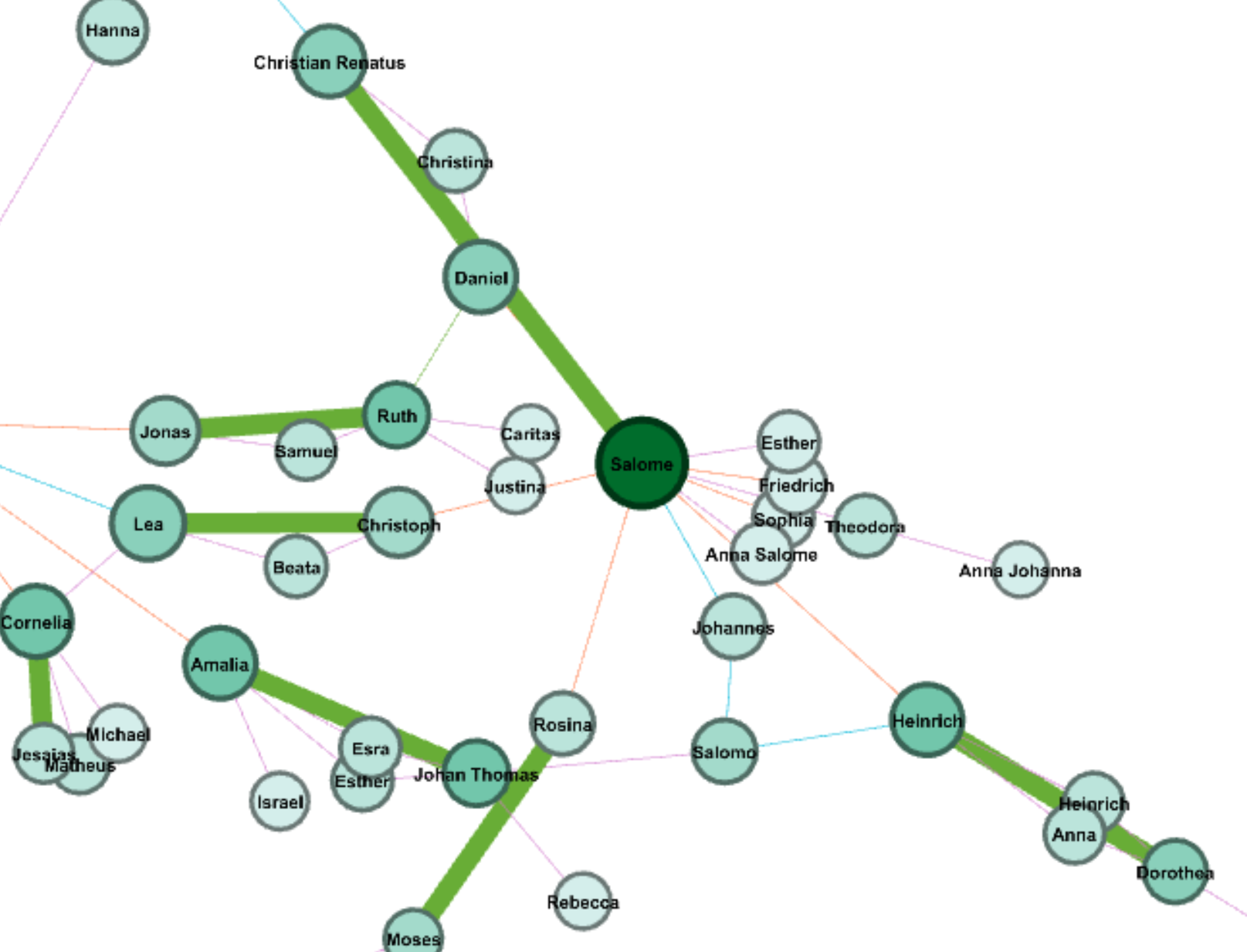
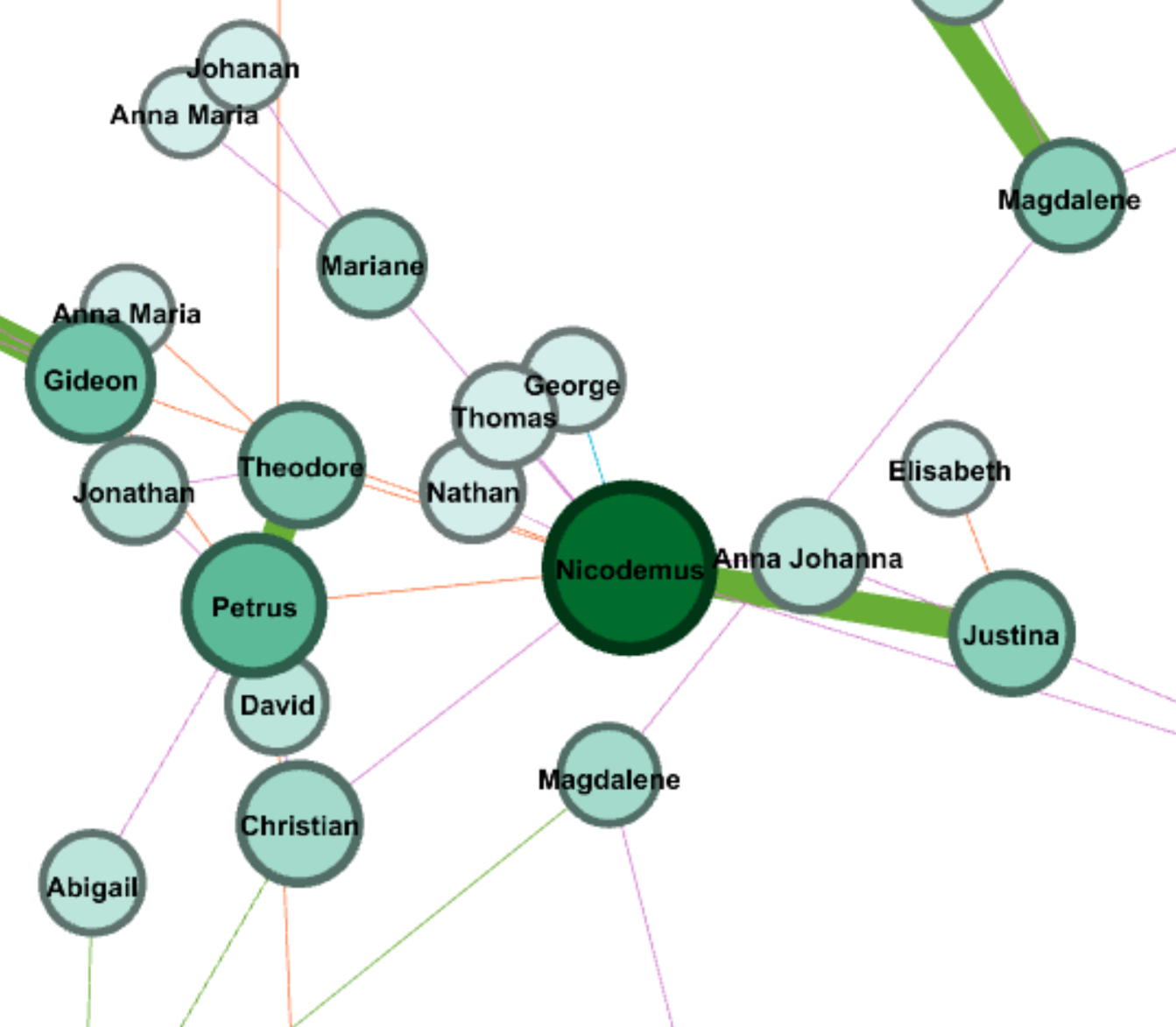
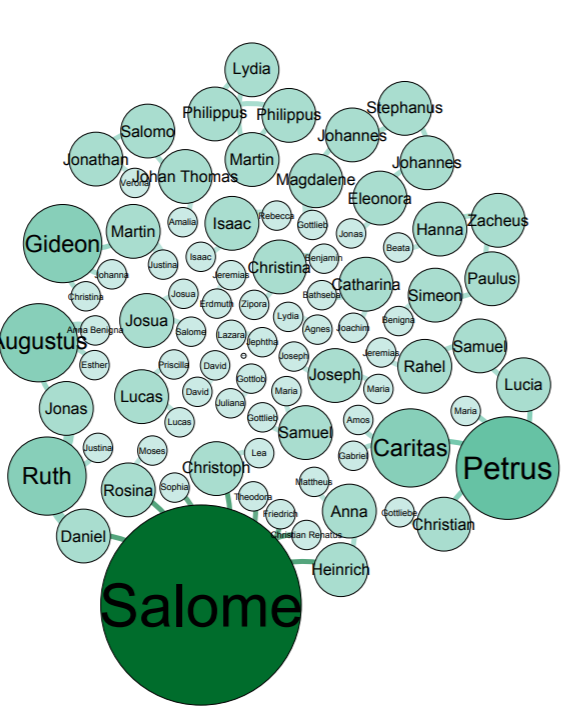
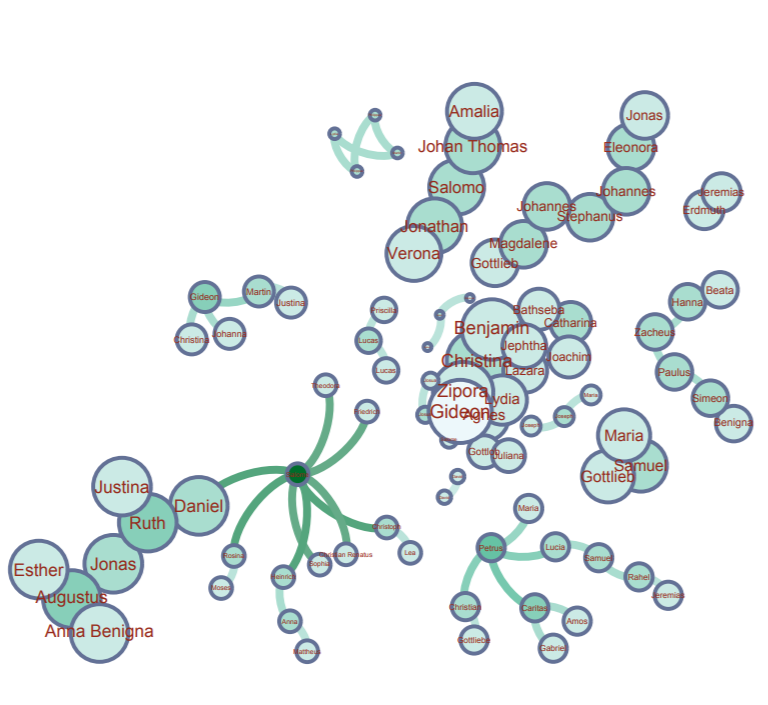
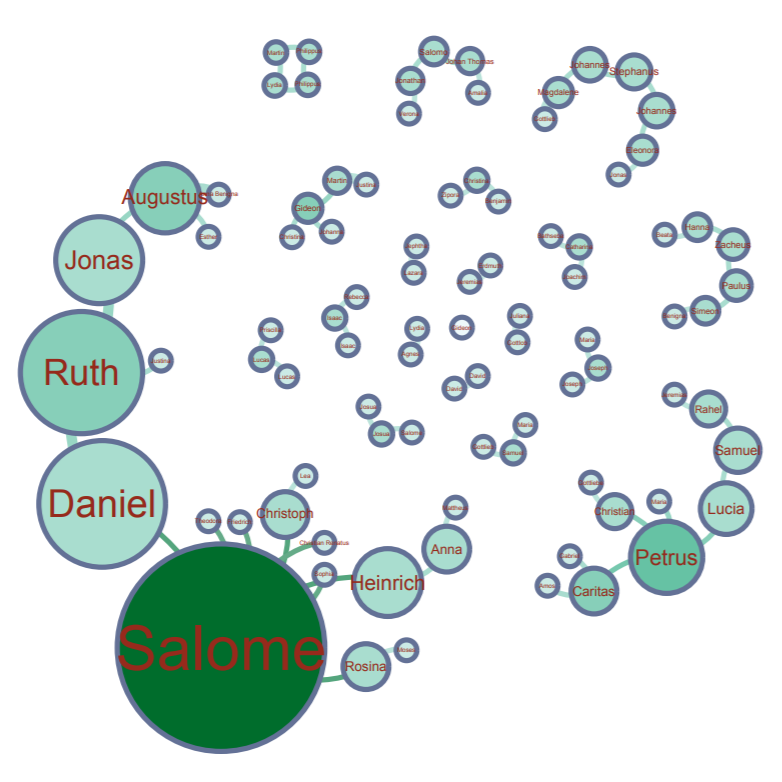
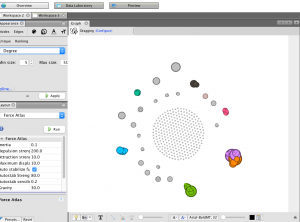
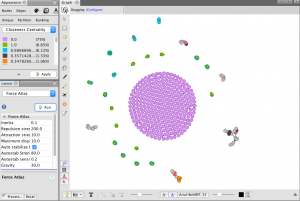
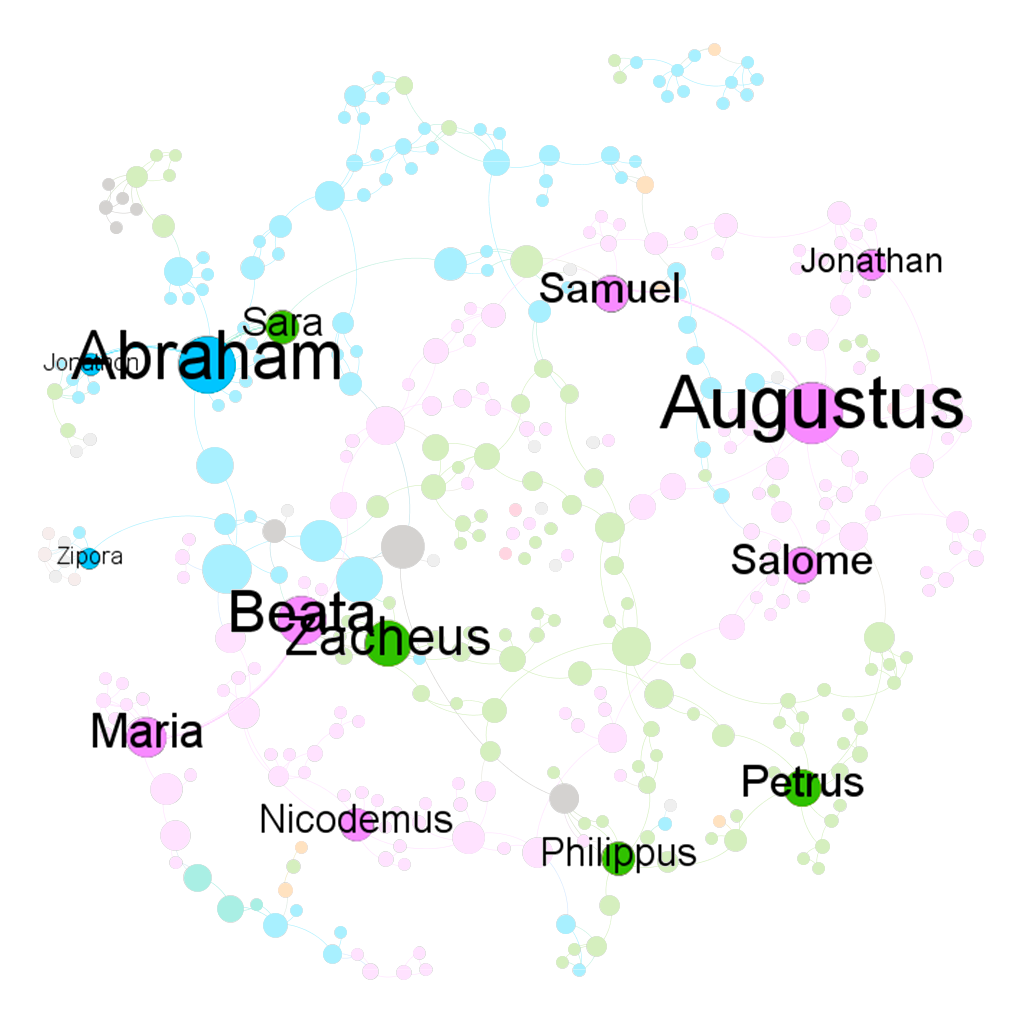
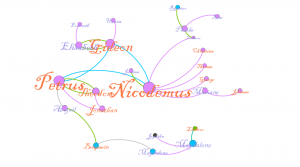
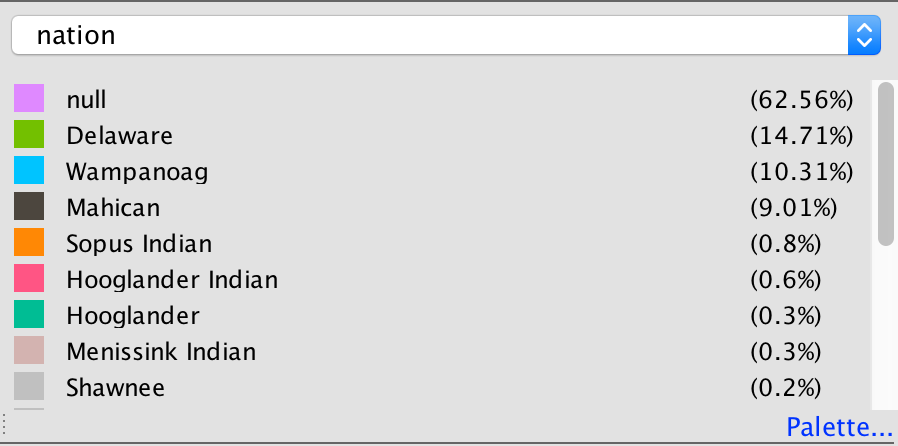
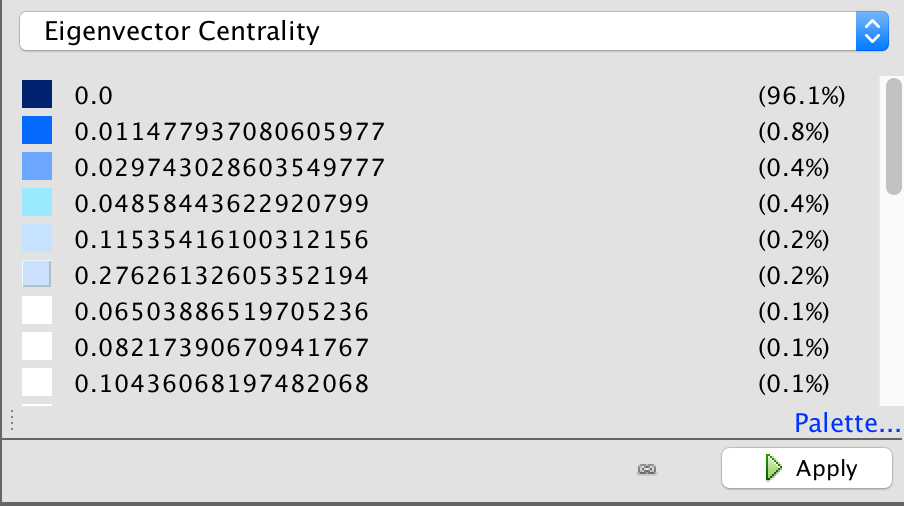
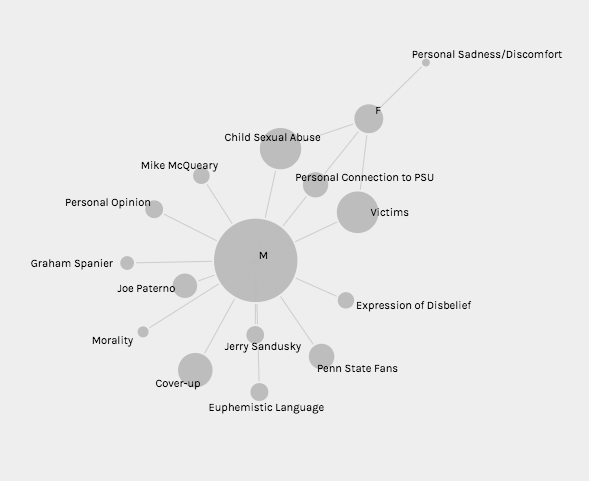
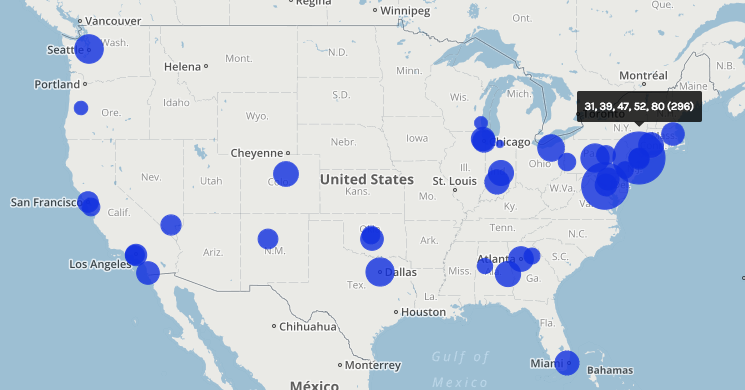
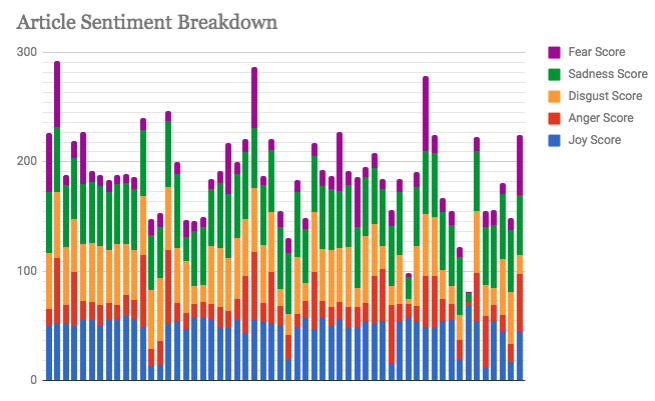
In my work with the “Map” and “Graph” features of Palladio, I encountered another problem coming in the form of automatic summation of sentiment values. As can be seen in the screenshots accompanying this blog post, node size was biased by the fact that multiple articles from the corpus came from the same location or shared common entries in other columns of my metadata. Thus, my visualizations involving node size as a reflection of sentiment were biased, and would have to be tampered with in some way. In the case of the “Map” view, the only solution I was able to come up with was to set up my visualization so that hovering over artificially large nodes (representing places like New York City) would show the sentiment values for the multiple articles that had their scores added together. In the case of sentiment summation as it related to theme or gender, I chose to go about solving this problem by incorporating a new set of simple stacked bar charts into my analysis. In doing so, I made it so that I would only have to worry about the dimensions of gender and platform as they pertained to theme (did not have to size nodes).
Once I had generated all of the necessary visualizations for the development of an argument that certain factors (like gender, time, and response platform) have had an impact on responses to the Sandusky scandal, I had to develop a logical fashion for presenting my visualizations and arguments as part of a narrative. In their article on narrative visualization, Segel and Heer explain the importance of narrative to digital humanities scholars by quoting Jonathan Harris, “‘I think people have begun to forget how powerful human stories are, exchanging their sense of empathy for a fetishistic fascination with data, networks, patterns, and total information … Really, the data is just part of the story. The human stuff is the main stuff, and the data should enrich it’” (Segel and Heer 1140). With this in mind, I realized that a multi-layered WordPress site consisting of several progressive magazine-style pages would be the most appropriate way to present my data. A site of this format allowed me to sequentially paint a picture of the real people who chose to respond to the Penn State scandal. Breaking the different dimensions of analysis into different pages helped me to contain my arguments and observations as palatable narrative bits that build to a broader understanding of the story of rhetorical conditioning in responses to the Sandusky scandal.
A final challenge in working with a project of this nature is that there is no available database that truly encompasses all of the tweets and articles written in response to the Sandusky scandal. Therefore, rather than work with a pre-compiled and “objectively complete” database, I had to gather the articles and tweets that would come to make up my corpus with no assistance. This style of corpus construction (during which I considered things like geographic location of the response) facilitated what I believe is the biggest flaw in my project (although it may have been an unavoidable pitfall): the subjective inflection of my corpus. In thinking about this, I was reminded of one of Johanna Drucker’s primary critiques of digital humanities work, “All data is capta, made, constructed, and produced, never given … So the first act of creating data, especially out of humanistic documents, in which ambiguity, complexity, and contradiction abound, is an act of interpretative reduction, even violence” (Drucker 249). In the case of my project, this data being “capta” led to two weaknesses in my final product — a disproportionate amount of responses from men and an uneven geographic distribution of articles (bias towards New York City and Washington, D.C.). Throughout my work, I was unable to find a realistic solution to this problem, so I elected to mention these flaws in my work under the “Conclusions and Further Work” menu on my WordPress site.
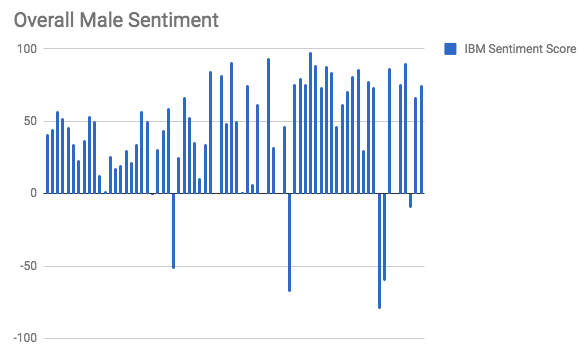
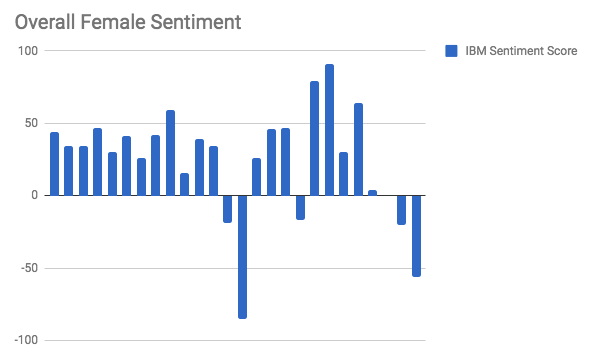
In conclusion, I believe my final product (WordPress site) was successful from a digital humanities standpoint. I hold this belief primarily because my visualizations help to generate a novel way in which to view the discourse surrounding the Sandusky scandal. In this way, my project harkens back to the assertions of Tanya Clement:”Sometimes the view facilitated by digital tools generates the same data human beings (or humanists) could generate by hand … At other times, these vantage points are remarkably different from that which has been afforded within print culture and provide us with a new perspective on texts that continue to compel and surprise us by being so provocative and complex — so human” (Clement 12). All in all, the conclusions that can be drawn from the admittedly author-driven narrative produced by my WordPress site helps to turn simple metadata into evidence of very humanistic behavioral patterns and motivation. Therefore, my final project has manifested itself as an example of the value of digital humanistic scholarship.