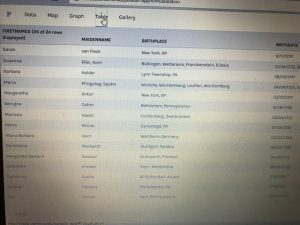
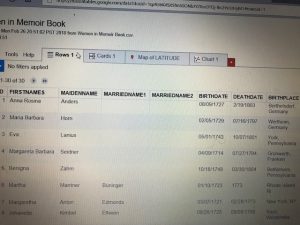
My data set is a collection of text documents (mostly speeches with a few recorded statements orations) regarding civil rights, delivered by a variety of divers authors. The authors include a Native American Chief from the 1850’s, Martin Luther King Jr. and even 2016 presidential candidate Hillary Clinton. In my data table I have included the descriptor categories:
Date
Author
Speech Topic/Context
Gender of Author
Location of Speech
Image of Author.
I felt like by using this combination of data, I could organize these texts in ways that would be meaningful for comparison and allow a reader to draw connections/ recognize similarities and differences between related topics and speeches.

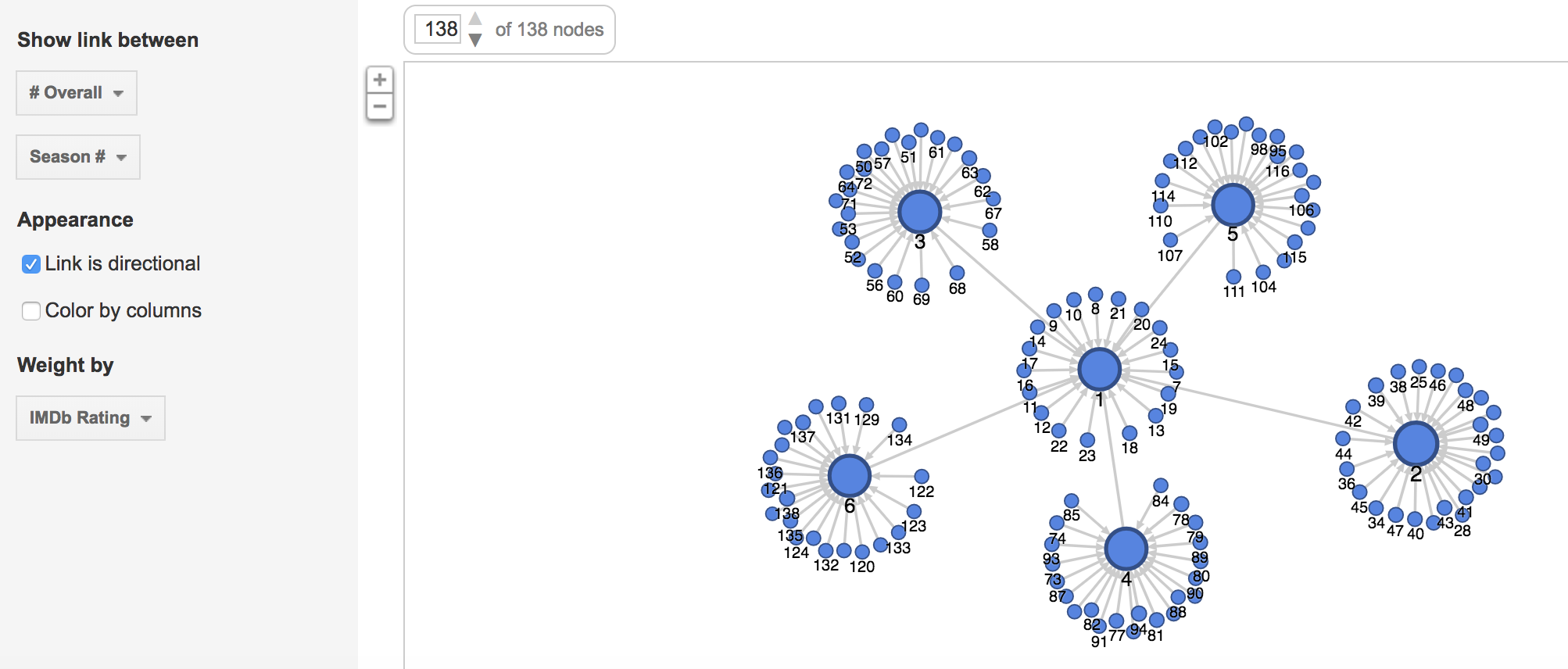
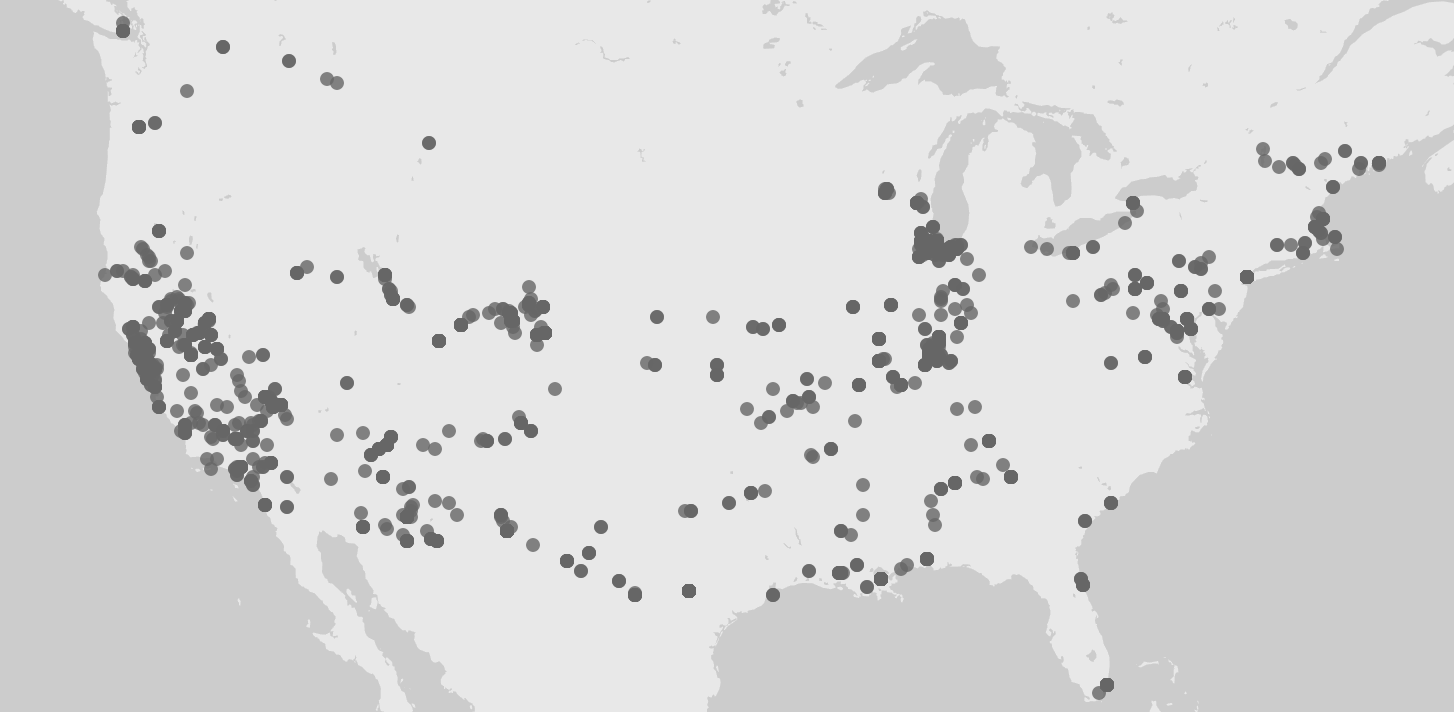
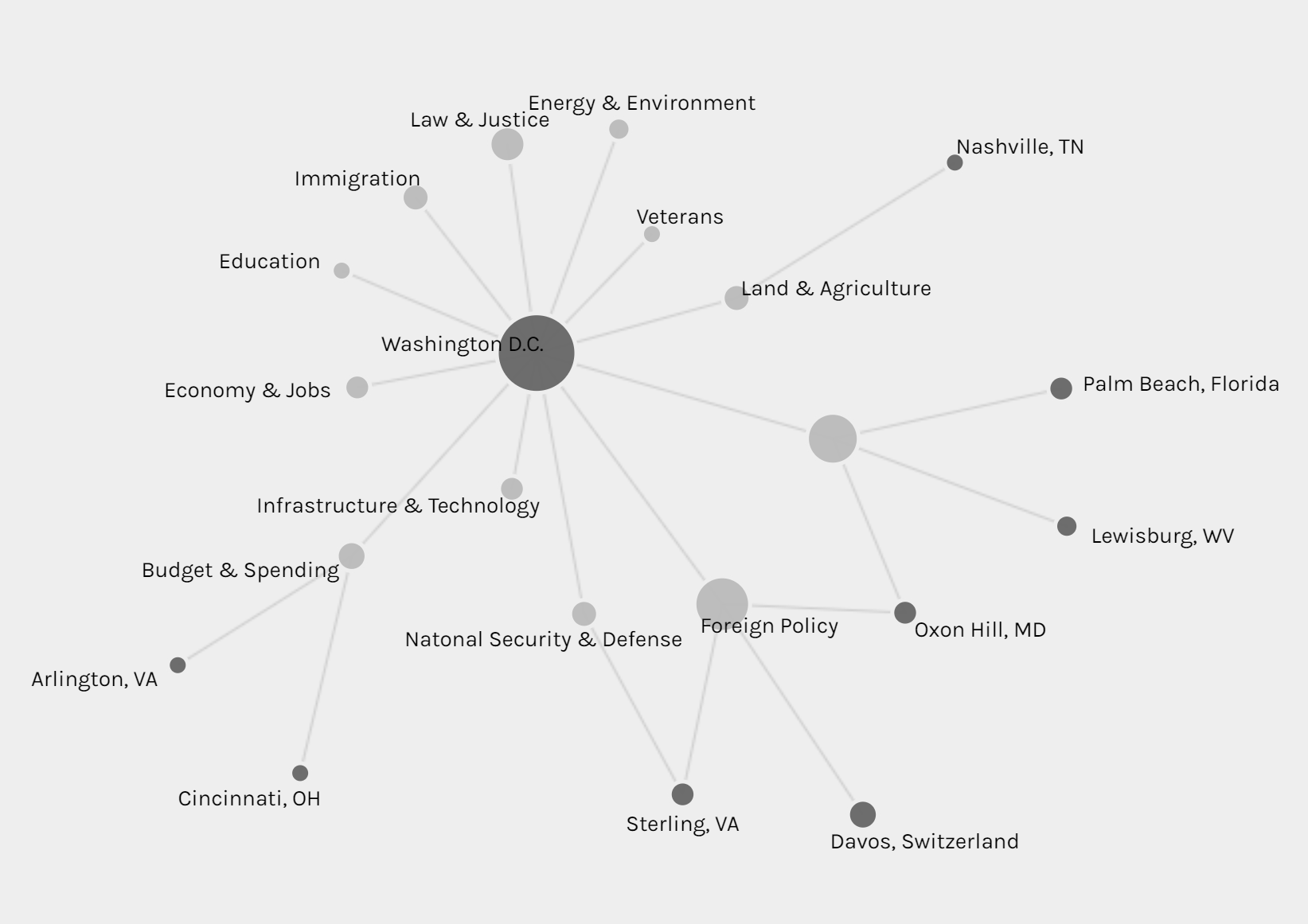
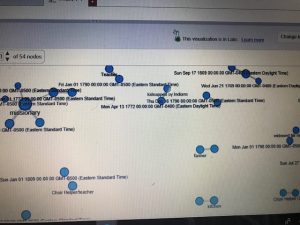
Above is a screenshot of a visualization I created on Palladio using the Graph tool. It links each speech with it’s latitude and longitude and shows which ones were given in the same location. It can also be filtered with the facet tool to show just certain speeches based on gender, topic, etc. The spatialization of this data provides a visual map for a reader with two dimensions that can be controlled to make inferences about whatever is desired to understand.
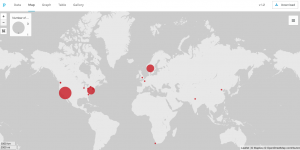
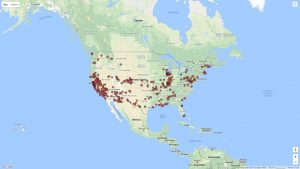
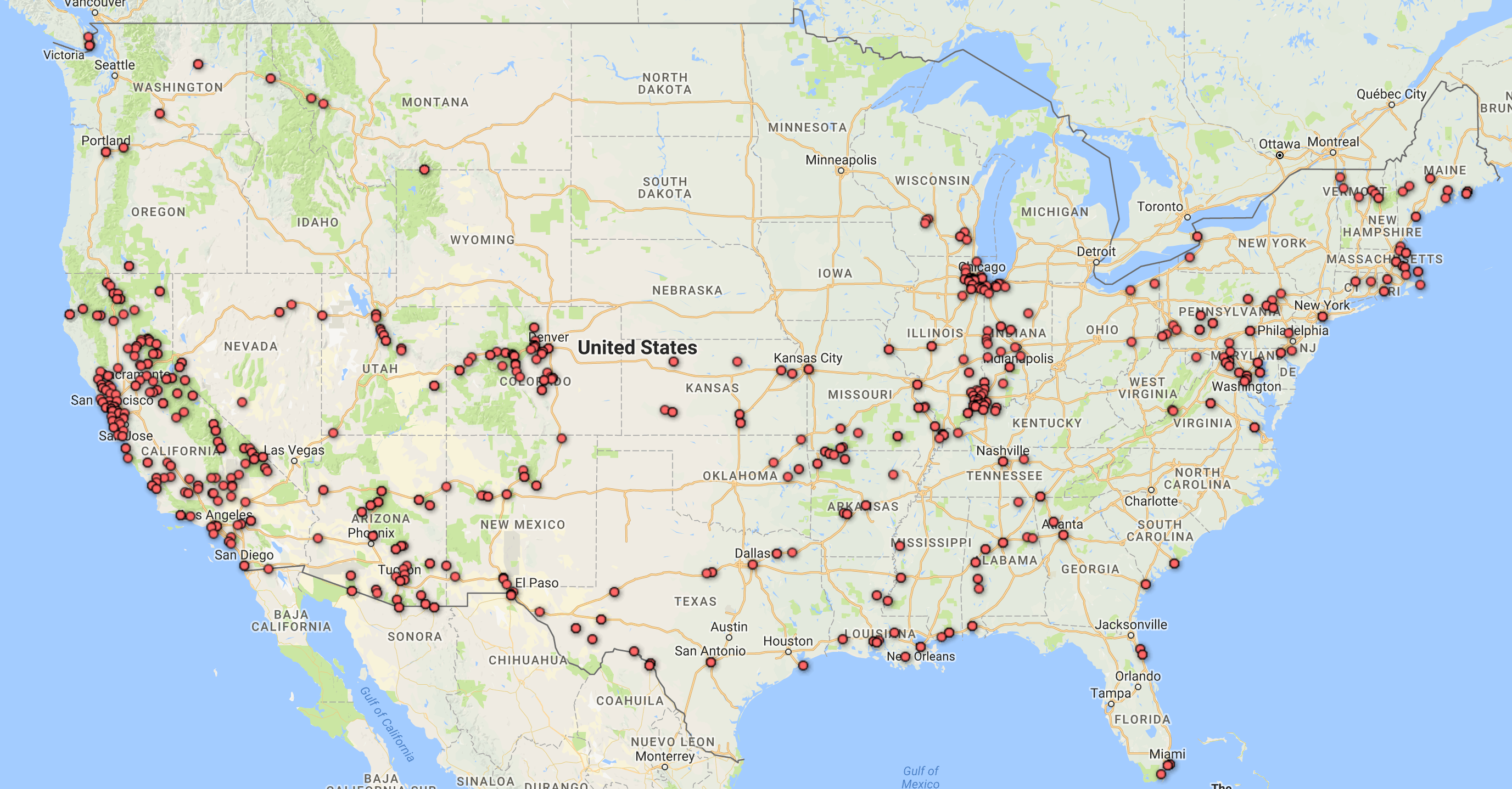
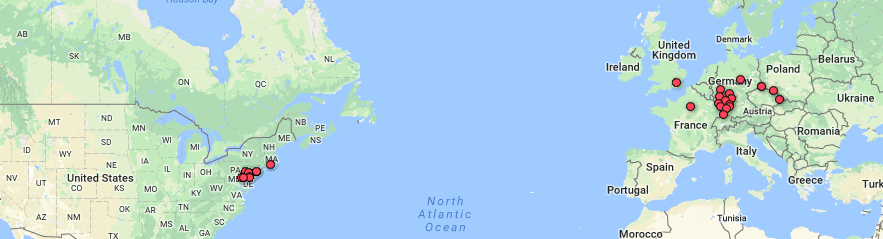
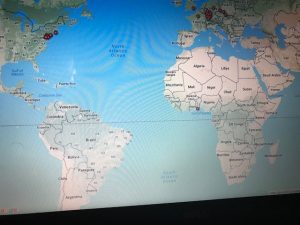
This next visualization is a mapping tool that shows the location of each speech’s delivery point on a world map. While this is a useful tool as it allows for the spatial awareness of a specific location to become perceivable for the reader, I feel it has some drawbacks as well. First off, the map is not labeled well at all, so without an extensive knowledge of geography, the map cannot stand alone well. Also, the large scaled dots are useful in the sense that they communicate volume of speeches given in a specific location, but they do not have a visible center and they span too large of areas to pinpoint the exact spot even if one did know exactly where that was on an unlabeled map. Google fusion tables has a similar feature and I feel that it does a better job although I have not completely figured out how to use it perfectly yet either.
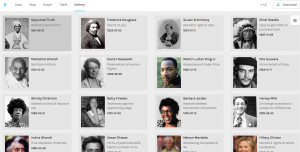
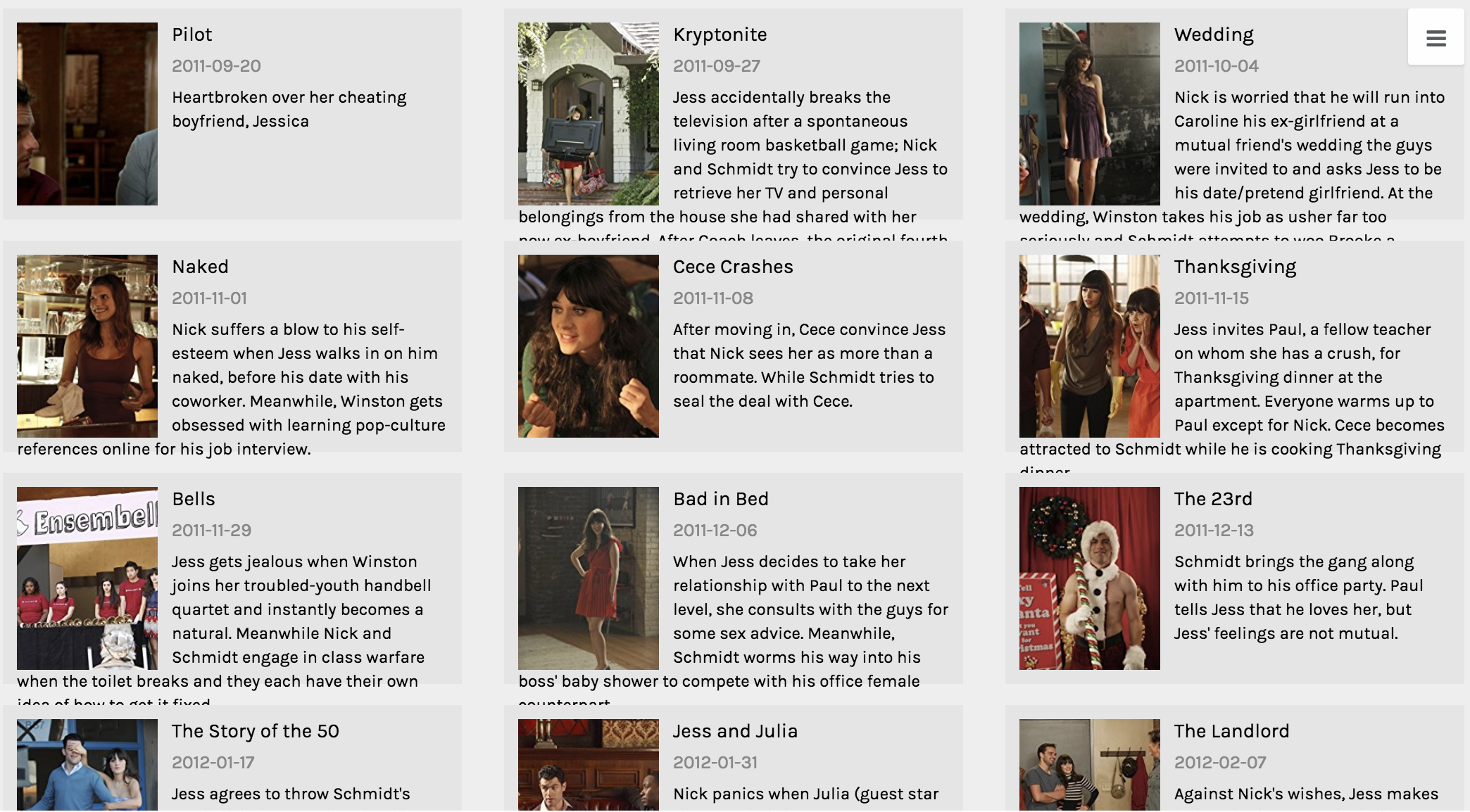
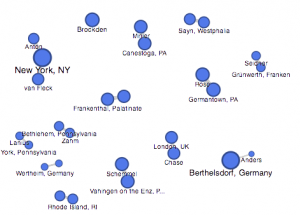
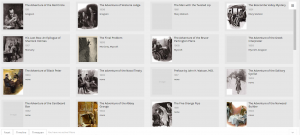
Above is my favorite of the tools I was able to use on palladio, the Gallery tool. It provides a template for a display of multiple pieces of information in a card-like format. As you can see, each card has a picture of the author of the text that it represents, along with the topic/context of their speech listed beneath their name. The cards are also organized by date (which is also listed visibly) to form a timeline of sorts within the larger visualization. Upon clicking on each card, it will also link the reader to a full text of the speech given by that author which allows for the further exploration and adds an interactive piece to the visualization to promote deeper research and understanding. I feel that there have been a vast number of times in my life when it would have been very useful to understand how to use this tool; both to sort information for my own purposes, but also for the ease of presenting it to other people.
As far as Drucker’s distinction between “knowledge generators” and “representations” I simply do not like these mutually exclusive classifications. I believe that something can be both at the same time. I think that these visualizations and this platform (palladio) embodies this idea of duality very well. Am I representing a form of data that already exists through a series of templates? Yes, and in that sense it is a representation. But by compiling this data, formatting it in accessible, user friendly ways, and then making it interactive to promote further examination and learning, I am also generating knowledge by was of access and opportunity. I find this to be very valuable and I think that it is certainly a noble pursuit.
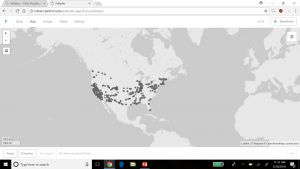
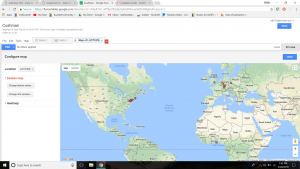


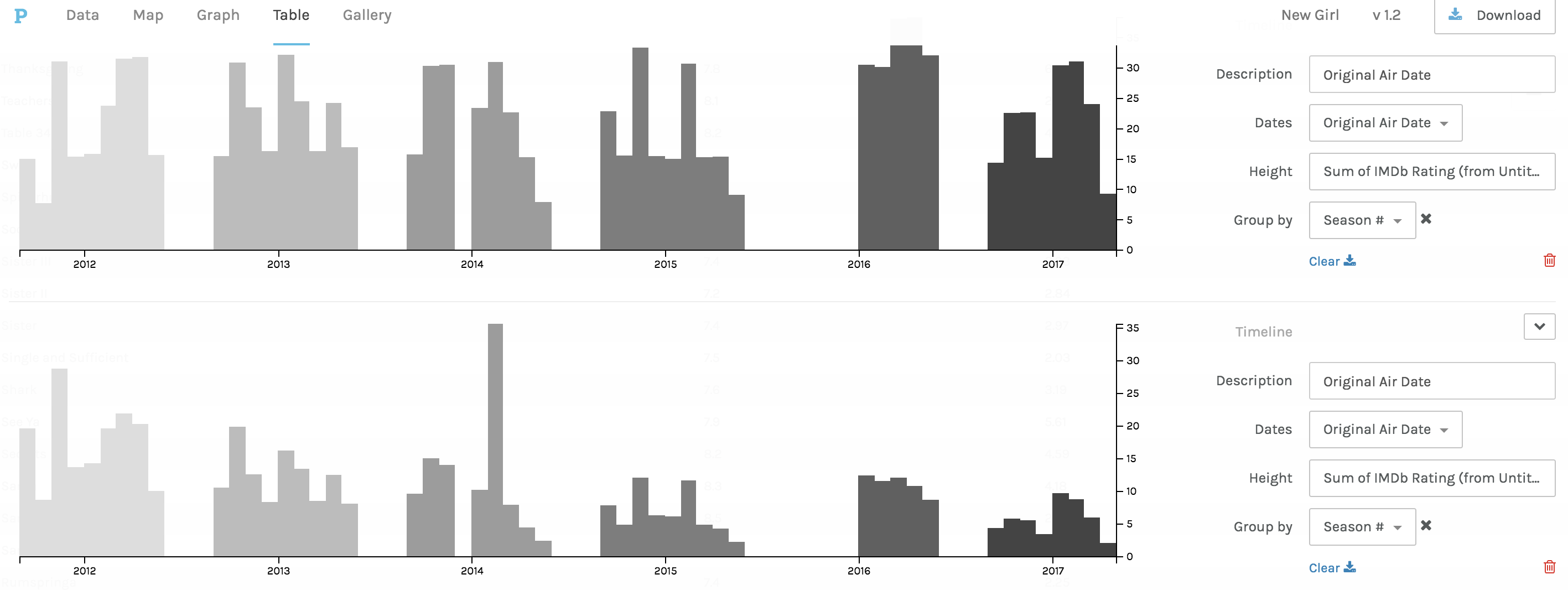



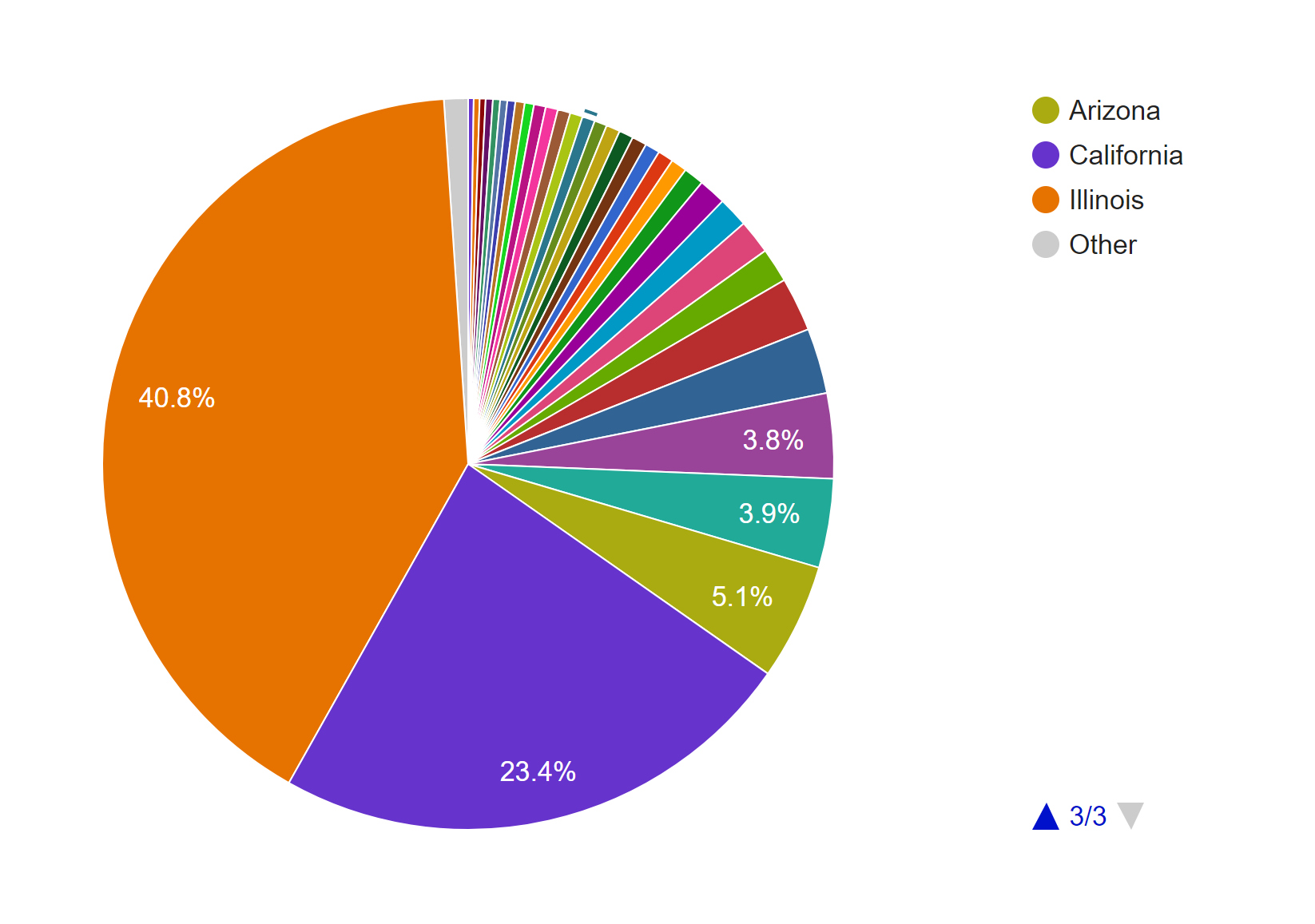

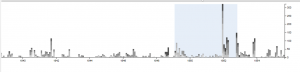
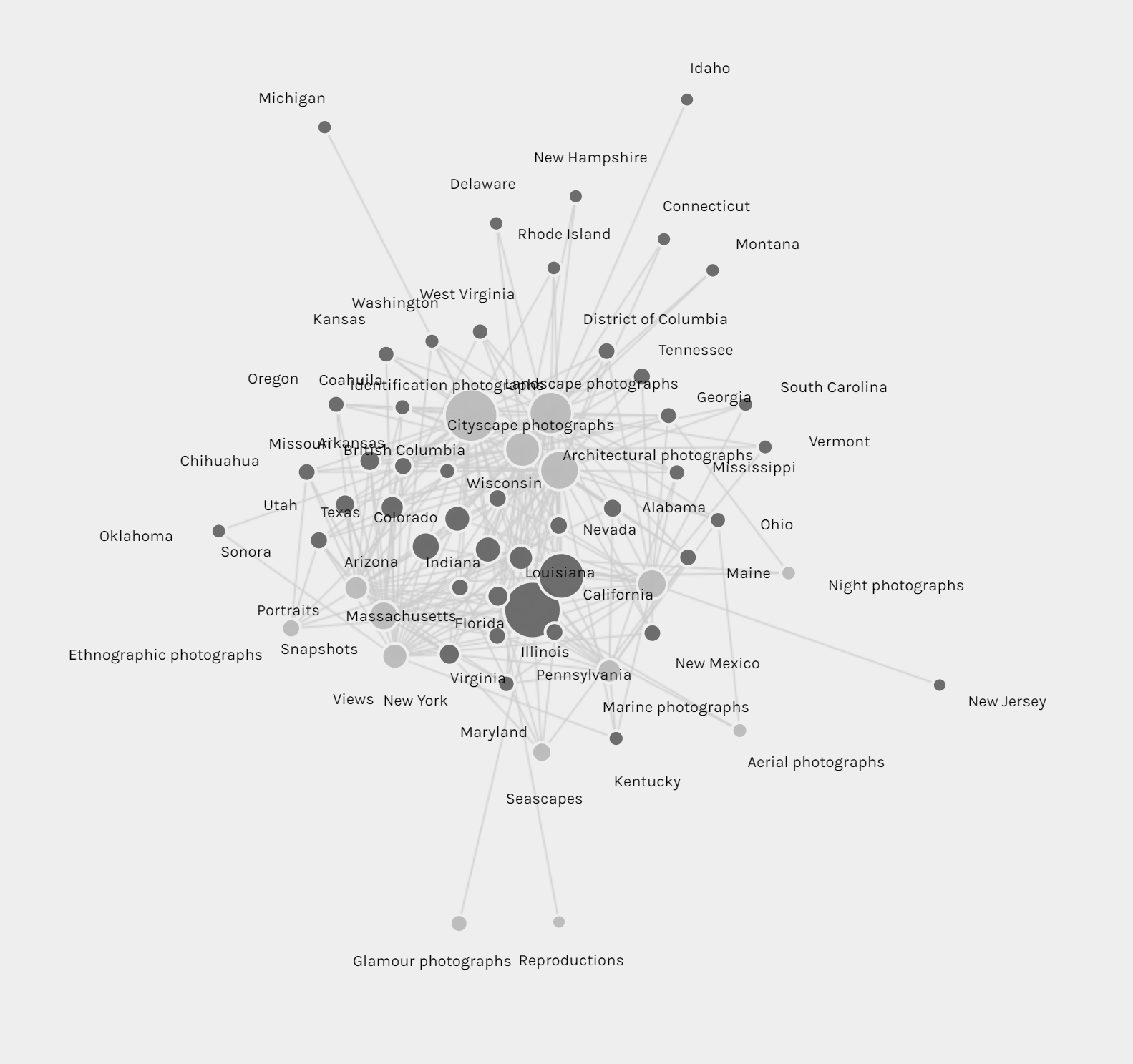
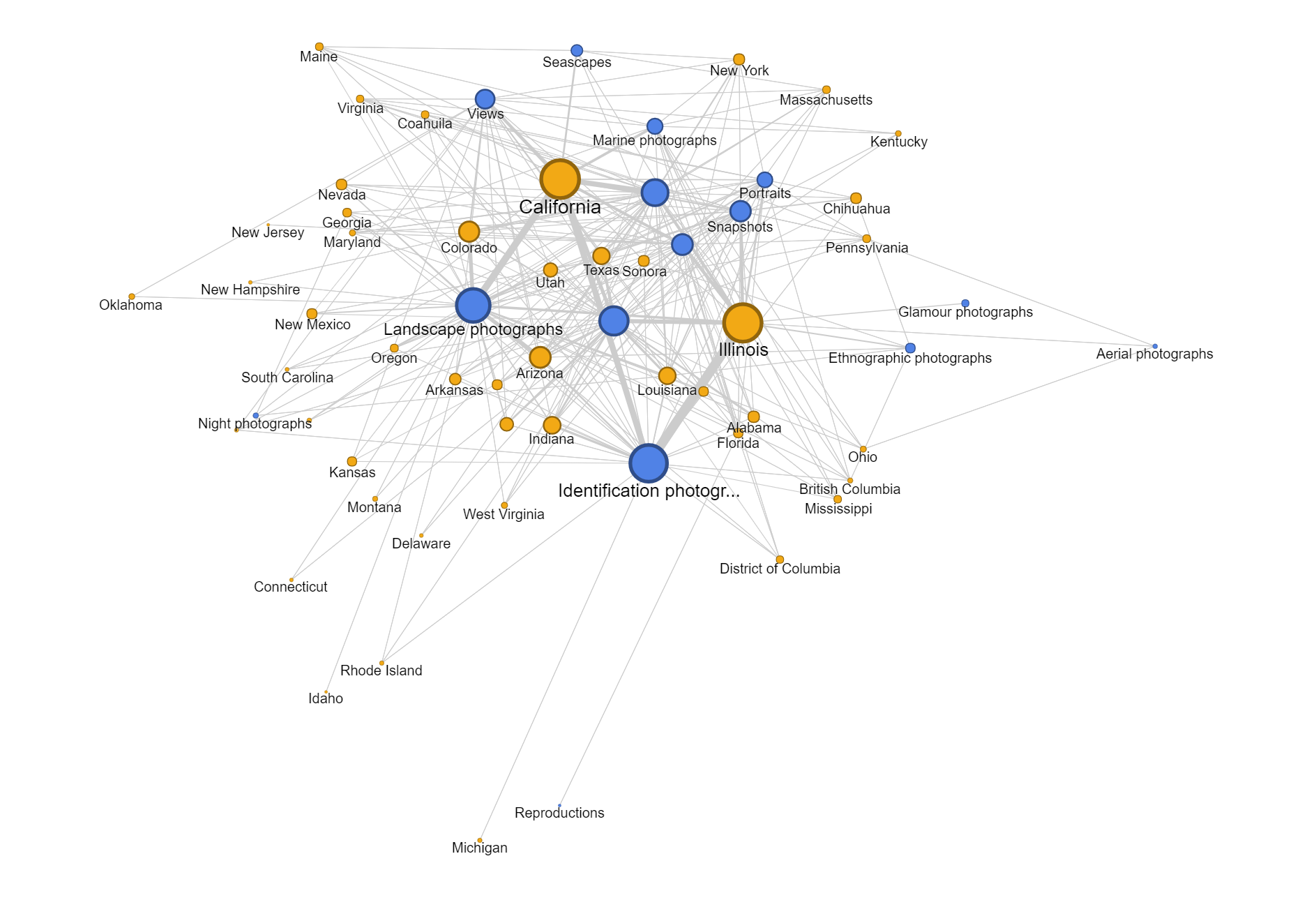
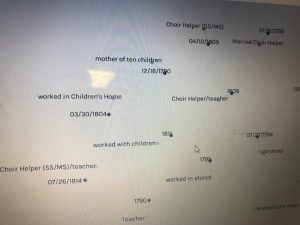
 Timelines of photos by date taken (below) and date archived (above).
Timelines of photos by date taken (below) and date archived (above).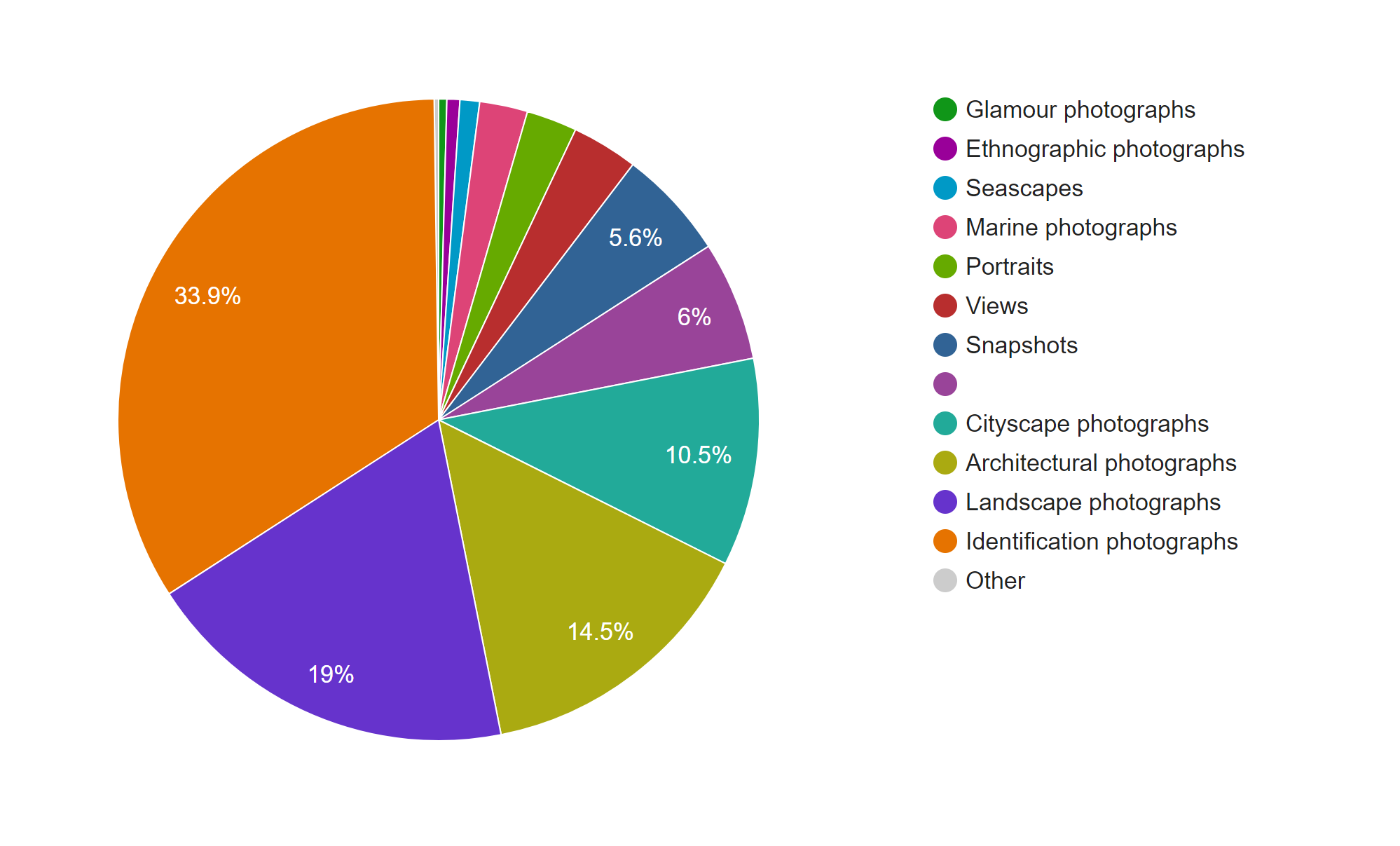
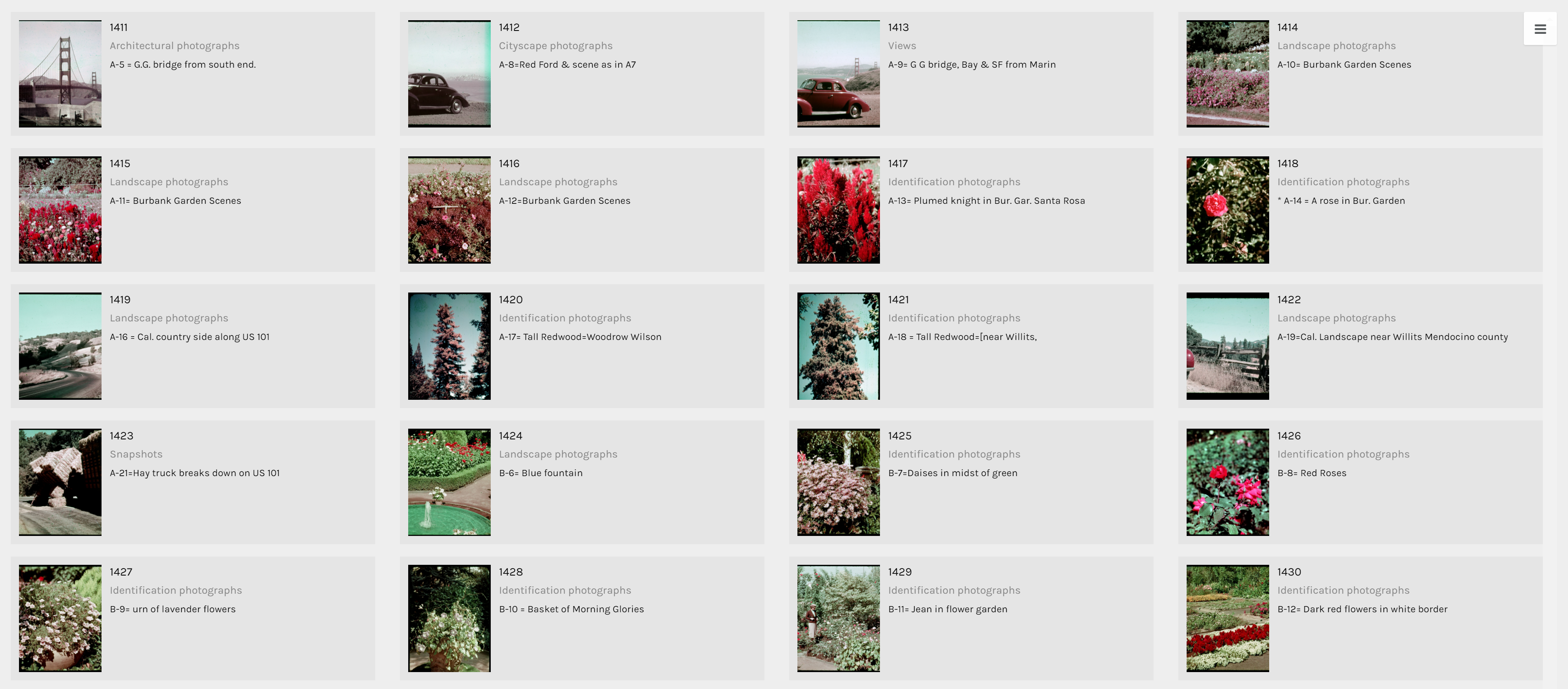
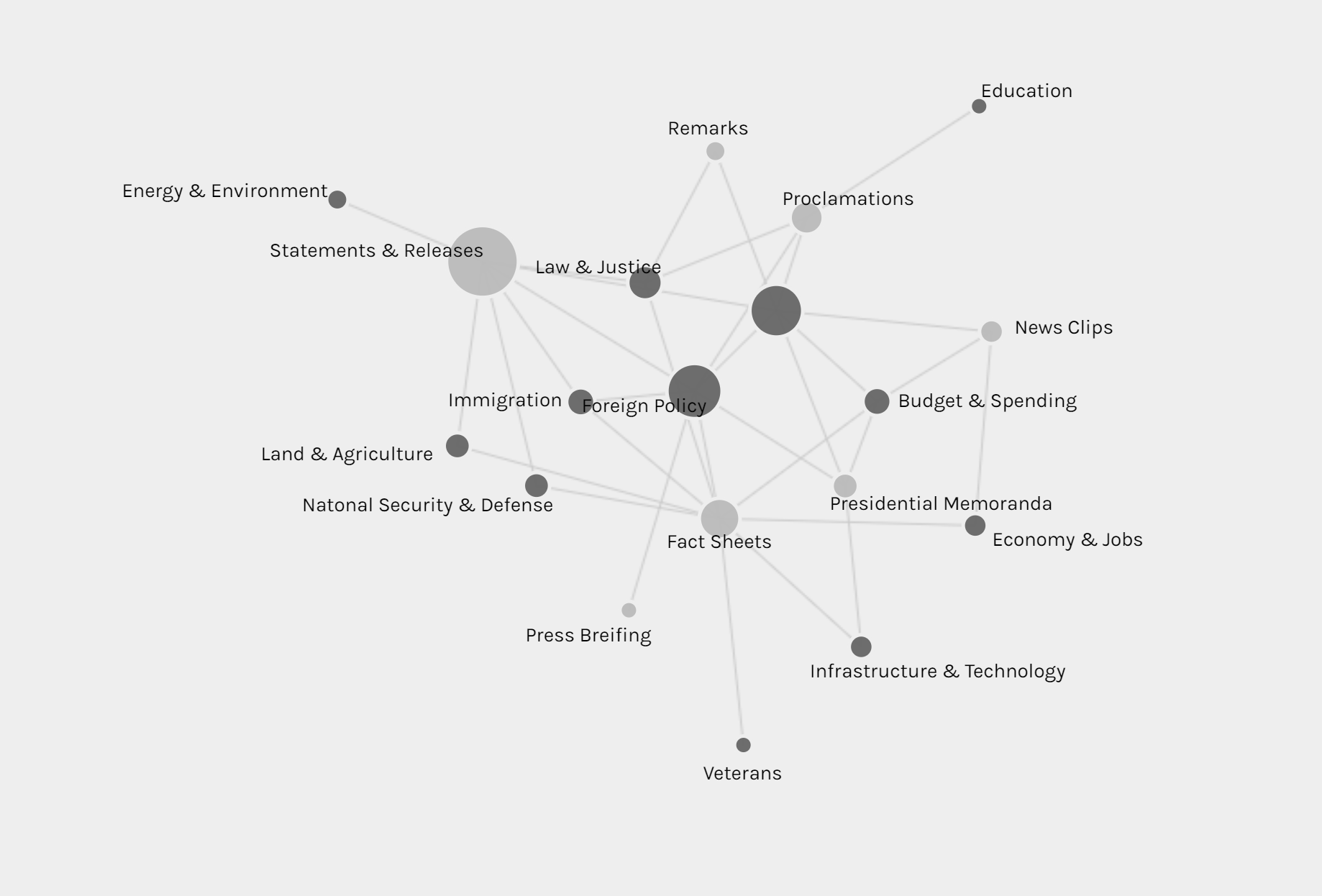
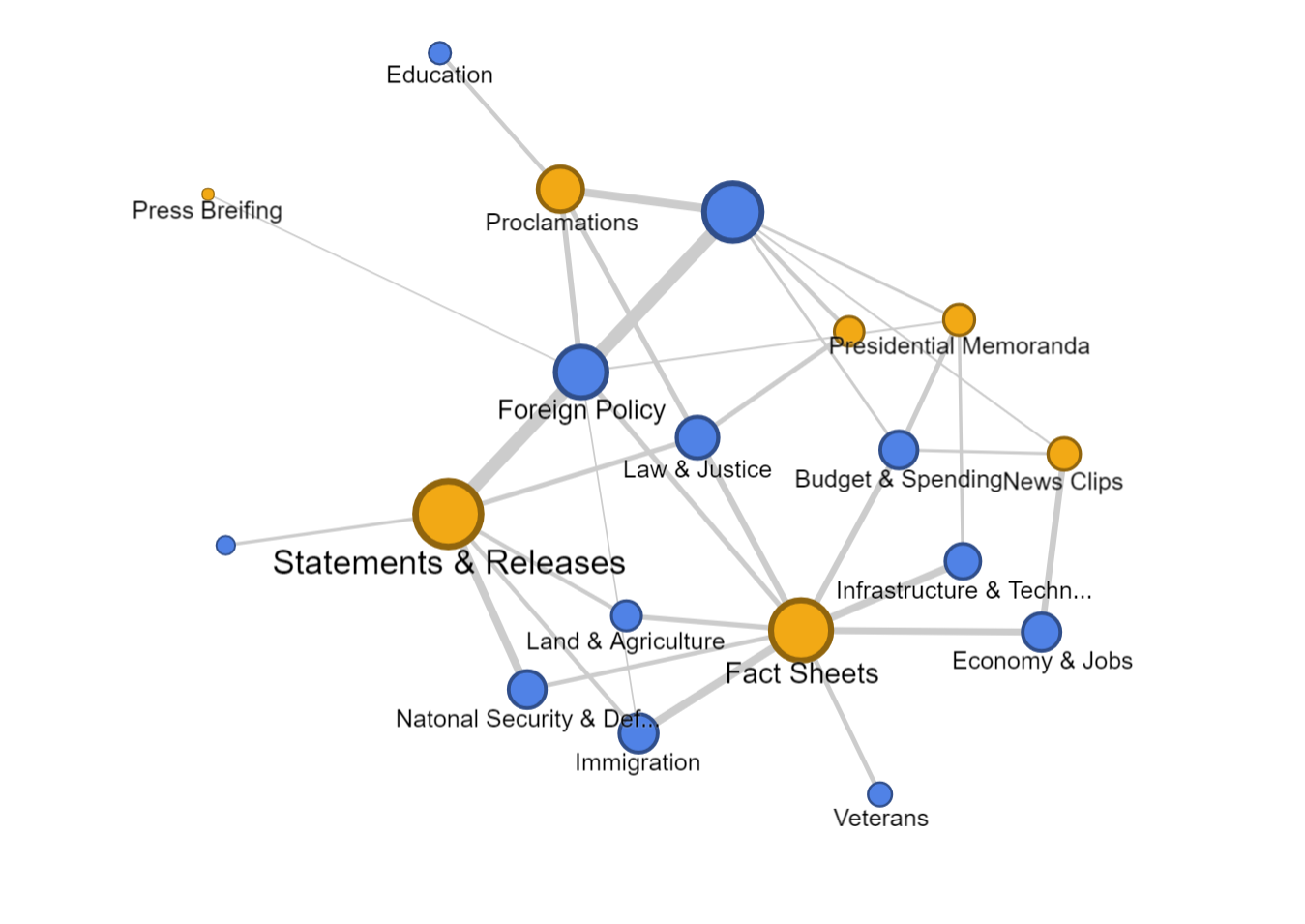



 le of Doyle.
le of Doyle.