Final Project Reflection
Research Question
Sir Arthur Conan Doyles’ collection of works that create the original canon of Sherlock Holmes is considered some of the greatest detective fiction ever written. It’s influences can be seen in mystery stories to this day. Holmes and Watson are household names that everyone comes to know at some point. This effect is not excursively form that original canon however. Its many adaptations are just as important for keeping the stories and concepts alive. This is what as known as a stories afterlife, and can in many cases an afterlife of great magnitude, such as this one, can give rise to just as much mythos as the original. One fun fact I found while completing this project was that the infamous Deerstalker cap and Calabash pipe that Holmes was famous for were never even mentioned in the original texts, stemming for the noteworthy plays done by William Gillette. This is just one example of how a work can be influence for neither better nor worse over time. In those adaptations however, some things were lost and gained, tropes formed and left behind all together. One hundred years of retelling can change a perception of a character dramatically. My goal of this project was to see how Holmes’s stories have changed over the years from a tone standpoint. To do this I did three things.
- First, I used analyzed the tone of the original work and read about the portrayal of Holmes within it
- I then would compare this to the tone of the adaptation in Voyant
- Lastly I would take note of the reception of the adaptation to see if people accepted this a the ‘new’ version of Sherlock Holmes
Methodology, Platforms, and Issues
After landing upon this goal, my first step was finding the adaptations that I wanted to work on. After doing quite a bit of research into plays, old tv shows, and forgotten movies, I found that getting a proper script or transcript of the production can be very difficult. After giving my computer probably more than one virus I decided to tailor my approach. I would go with the most popular Sherlock Holmes works , find their adaptations, and then use those which had public domain or easily accessible scripts or texts. I also already had all of the texts from the novels thanks to Project Gutenberg and my previous work with the Sherlock Holmes’s canon. My final approach ended up being a combination. For the meat of the project I decided to focus on the most successful novels since they have been thoroughly adapted. I also finished the slideshow with a overall view of the project
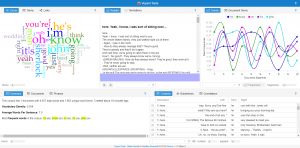
My next step was deciding on appropriate platforms for my project. I knew from the start that Voyant would be a very handy tool for as I was primarily analyzing texts. In the end Voyant would be one of my favorite aspects of my project as it was seamless to embed and looked gorgeous with no tweaking to it. The way I used Voyant was to give the reader something easily digestible upon first inspection of a work. It allows the reader to get a loose understanding and form and preconception of the adaptation or original work that they can then use to guide their thoughts when looking at the slightly more complex visualizations. This was not the main focus on my idea at first, but the way Voyant seamlessly embeds into the slideshow cannot be overstated and it adds another level of interactivity.
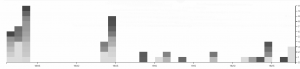
I also knew I wanted to do a timeline since the concept of an afterlife went hand in hand with a timeline. Luckily we had already worked a lot with Timeline JS which was the perfect platform for my project. Timeline JS is an incredibly user friendly platform that saved me a lot of time that would have otherwise been spent formatting websites. My biggest issue with timeline JS, and this is really an issue with my concept, is that a chronological layout makes sense at first, but limits my ability to control what the user sees, and that can lead to some jumbled information being reported and the visualization can lose focus.
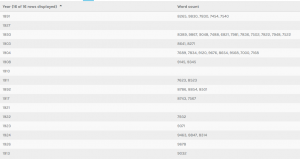
Sentiment analysis became a problem in and of itself. Jigsaw never looked very pretty to me and when I heard other students were using IBM Watson I decided that would be my tool of choice. IBM Watson was very hard to tame in its application form, I spent hours in terminal with curl trying to get it to work, but in the end had to use the default web version unfortunately. The web version felt slightly stripped down, but was enough for me to work with. It provided scores in a range of emotions that could loosely describe the tone of a body of text. I used these scores to judge what the over all impression the work would leave on a person and used that as my basis for tone.
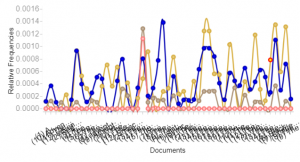
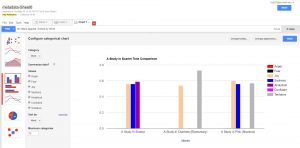
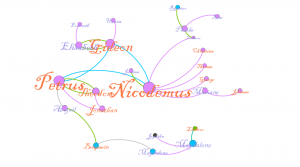
With that figured out, my last step was how I would present my comparisons. After looking at our previous platforms I decided that Palladio would serve me best as a flexible, simple, and user-friendly platform that accepted unformated csv files. I settled on using the graph functionality of Palladio. I pulled the graph sit created to compare the tones of an original to its adapations.
My last platform became Google Fusion Tables. My data, while interesting, was not very complex. This meant two things, I needed somthing to make data that was not quite as flashy appear like that at a cursory glance from a reader, and something that could present that data cleanly and not over complicate it. This suit google fusion tables simple charts perfectly.
In conclusion, I found this project to be an learning experience for a CS major such as myself. This class is well outside of my comfort zone, so I’m proud of what I’ve created. I tried to not draw too many conclusions on the visualizations I provided as I want them to speak for themselves, but I fell as if they show a clear deviation in the personality of Sherlock Holmes. My original goal was simply to explore whether this deviation existed and I think I succeeded on that front. Some critiques of my own process would be to become much more intentional with my research and plan my moves for the future, as I ended up doing a lot of research and wasting a lot of time with tools that I would end up discarding. My biggest downfall was that I think I failed to convey my own opinions of the subject matter in attempting to not force them on the reader, but that could be up for debate.I also feel that my major critique of my visualization is that it lacks interactivity on an immersive level outside of clicking through a slideshow, but other than that I feel as if the project turned out excellently.
Screenshots:
Bibliography:
“Canon of Sherlock Holmes.” Wikipedia, Wikimedia Foundation, 10 Apr. 2018, en.wikipedia.org/wiki/Canon_of_Sherlock_Holmes.
extensive use of this website: https://www.springfieldspringfield.co.uk/
metadata: https://docs.google.com/spreadsheets/d/1kQfdooVqIRx9hcd1z4Ot3XFDQILRTtcI6GapqkF3x0I/edit#gid=2047249578
timeline js skeleton: https://docs.google.com/spreadsheets/d/1MF4i-mdUfti8Li1FNT1O65a-WFFPa16ZUhUfkWwzVuw/edit#gid=0
voyant : http://voyant-tools.org/
palladio: http://hdlab.stanford.edu/palladio-app/#/visualization

 le of Doyle.
le of Doyle.