Link to final project website: http://humn270finalprojecthaipujunjie.blogs.bucknell.edu/
Link to database: https://drive.google.com/drive/folders/1rFmSEDr48kAB5f0VuYG6DrHXHAFQoPEG?usp=sharing
Trump News
It has been more than 300 days since Trump took office, and during those 300 days, the white house has been publishing many news related to him. We are familiar that Trump has been blaming new company like CNN for publishing “fake news”, so I think it will be interesting about to research about what kind of news is posted by the white house and how is the news posted by the white house related to Trump’s schedule. And because Junjie is also researching about Trump’s tweet, we can combine our result together to see the similarity and difference of both official and unofficial side of Trump. Therefore, I started to collecting news from the news section of the white house’s official website and due to the limit of time and better fitted with Junjie’s data, my data includes the news posted from October 2017 to February 2018.
Data Collection
Data collection is usually a time taking, boring and repetitive job before fancy graphs are made, but necessary and important at the same time. It is convenient to used ready-made data, but during my final project, it’s worth to spend such long time to collect data. By collecting data by myself, I know more details about each file so later I can know if the graphs made by different tools actually make sense and more importantly when weird things happened, it is easy to find out the reason of that. Just like what we have learned this semester, in Johanna Drucker’s reading, data visualization can mislead viewer, but by collecting data by myself, I could related real issues with the graphs instead of making wrong inductions.
Google Fusion
Google Fusion is an online tool which provide many basic statistical tools for me to visualize the metadata.
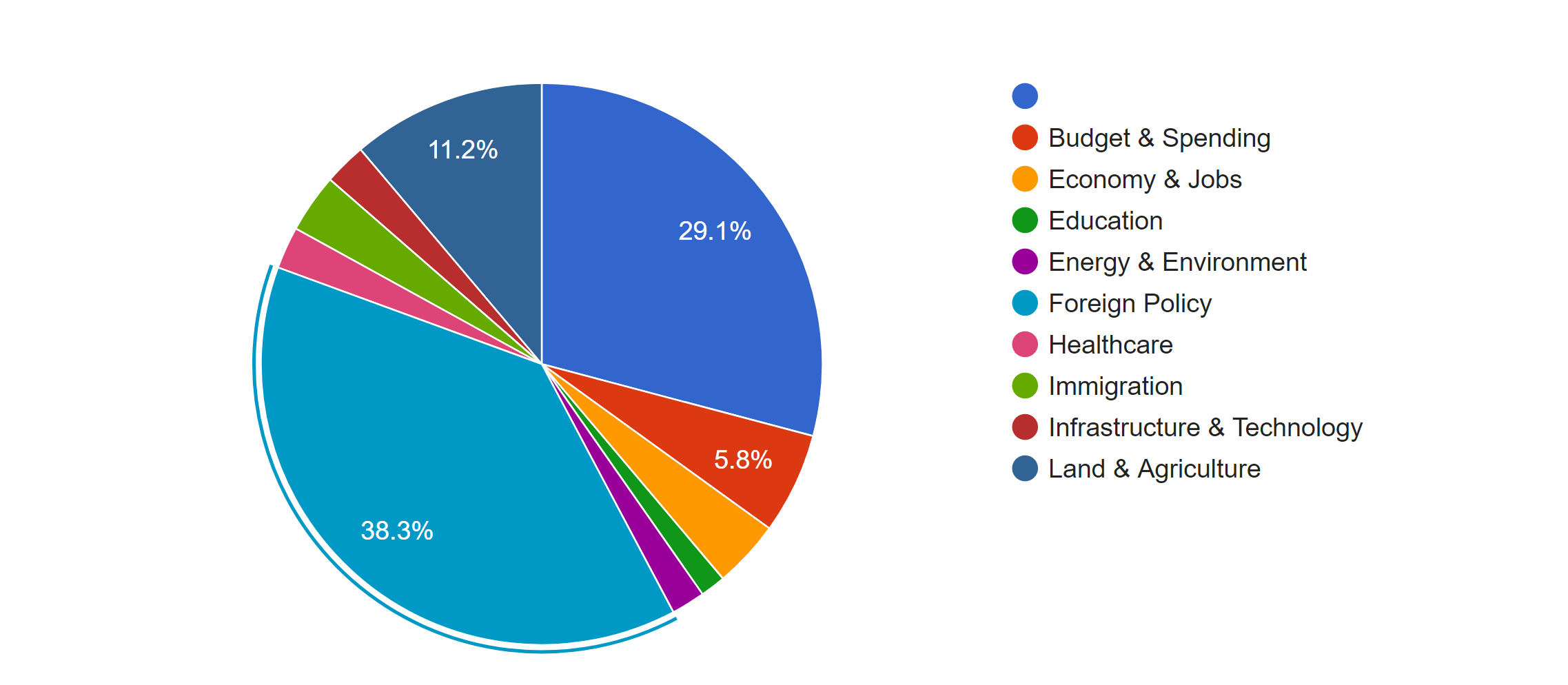
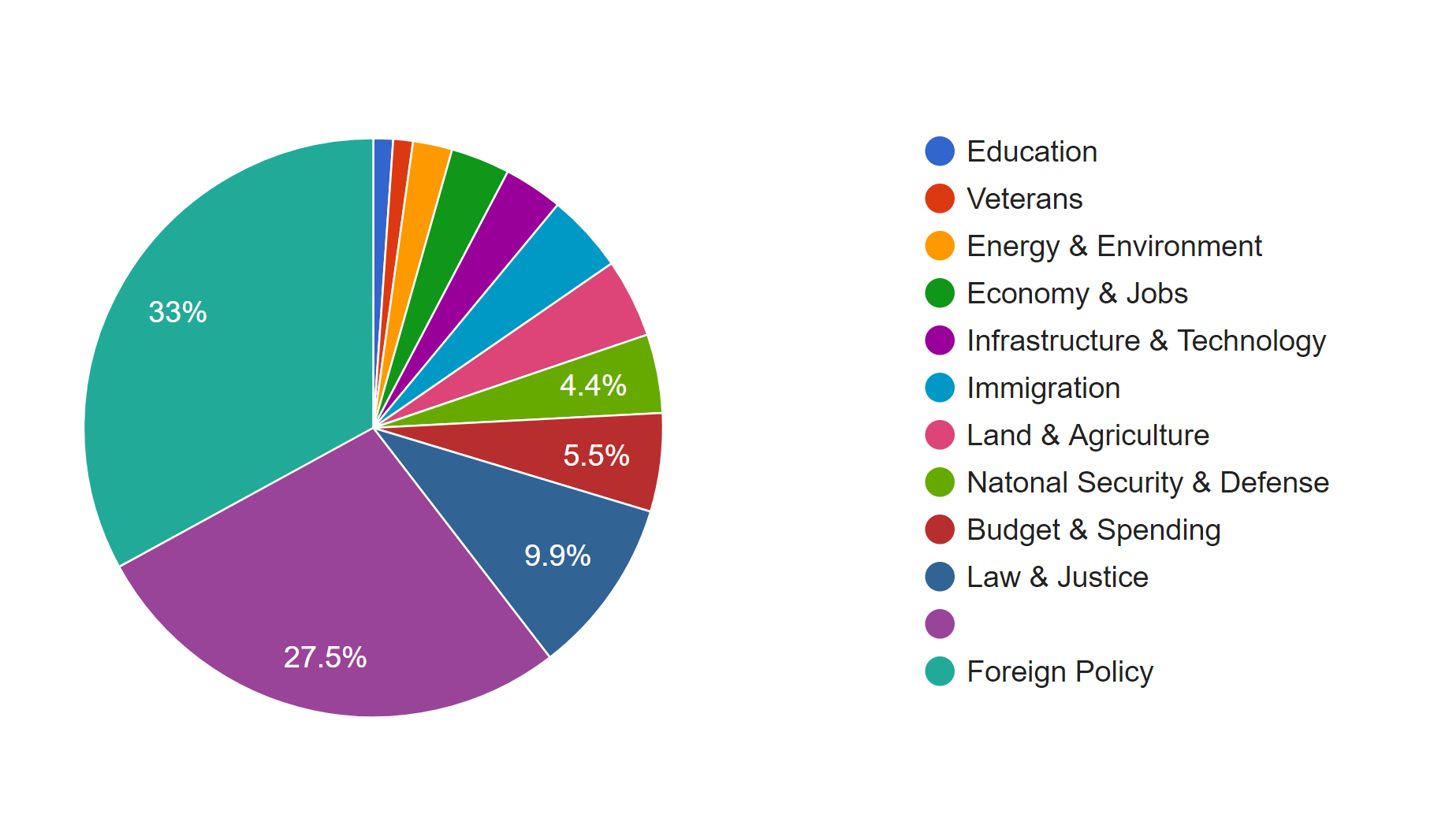
The first pie chart shows the distribution of news in different topics. It is obvious that Foreign Policy covers the most of area of the chart, which means it’s the issue of most news, because in the last several months, Trump visited many foreign countries and has been talking to many presidents or officials from other countries. Due to the hurricane happened during the end of 2017, land of many states were destroyed; therefore, president Trump published many relief plans to deal with the disaster. Therefore, there was also a lot of news about land and agriculture. As a famous merchant, Trump also focus a lot on the economy, so budget & spending and economy & jobs were also mentioned a lot.
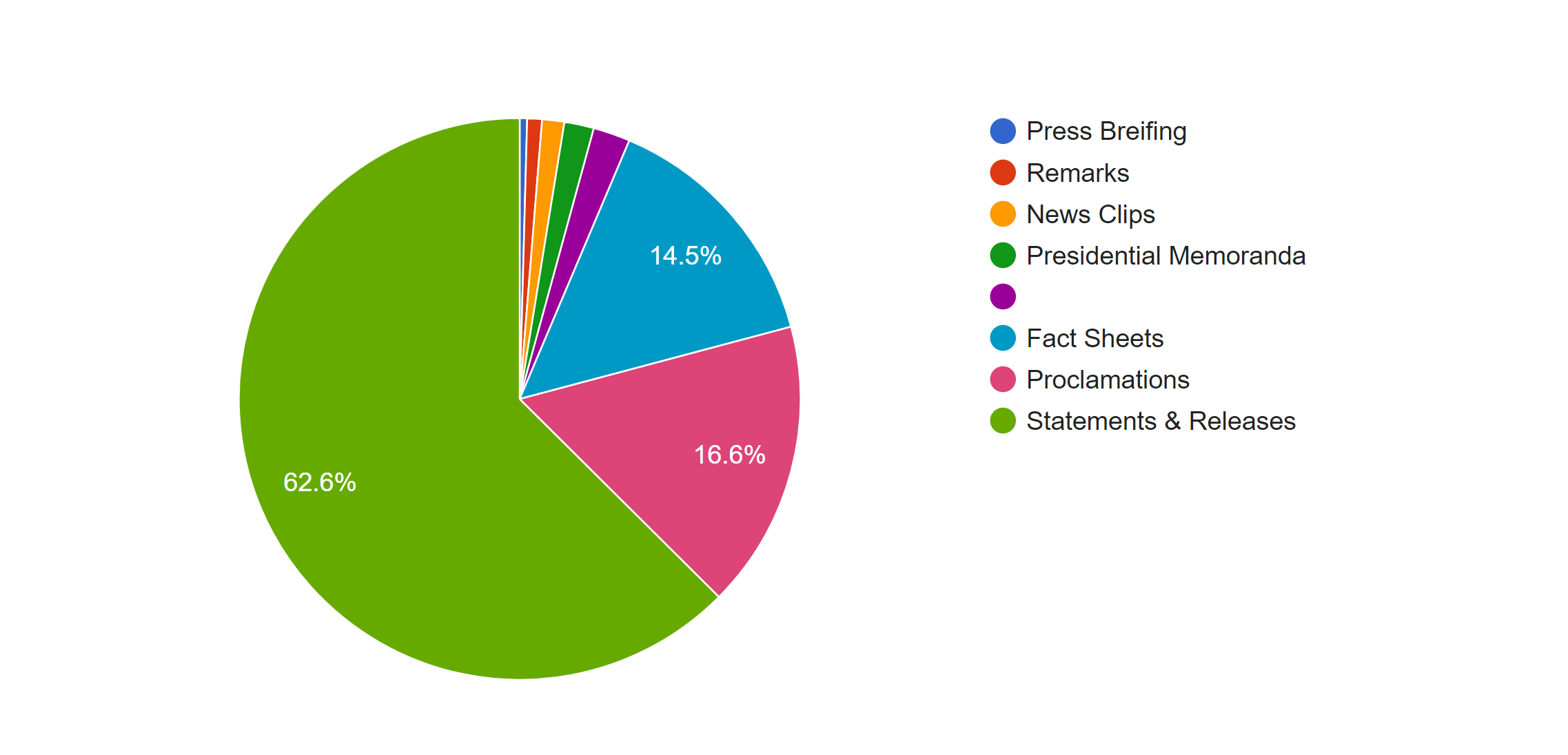
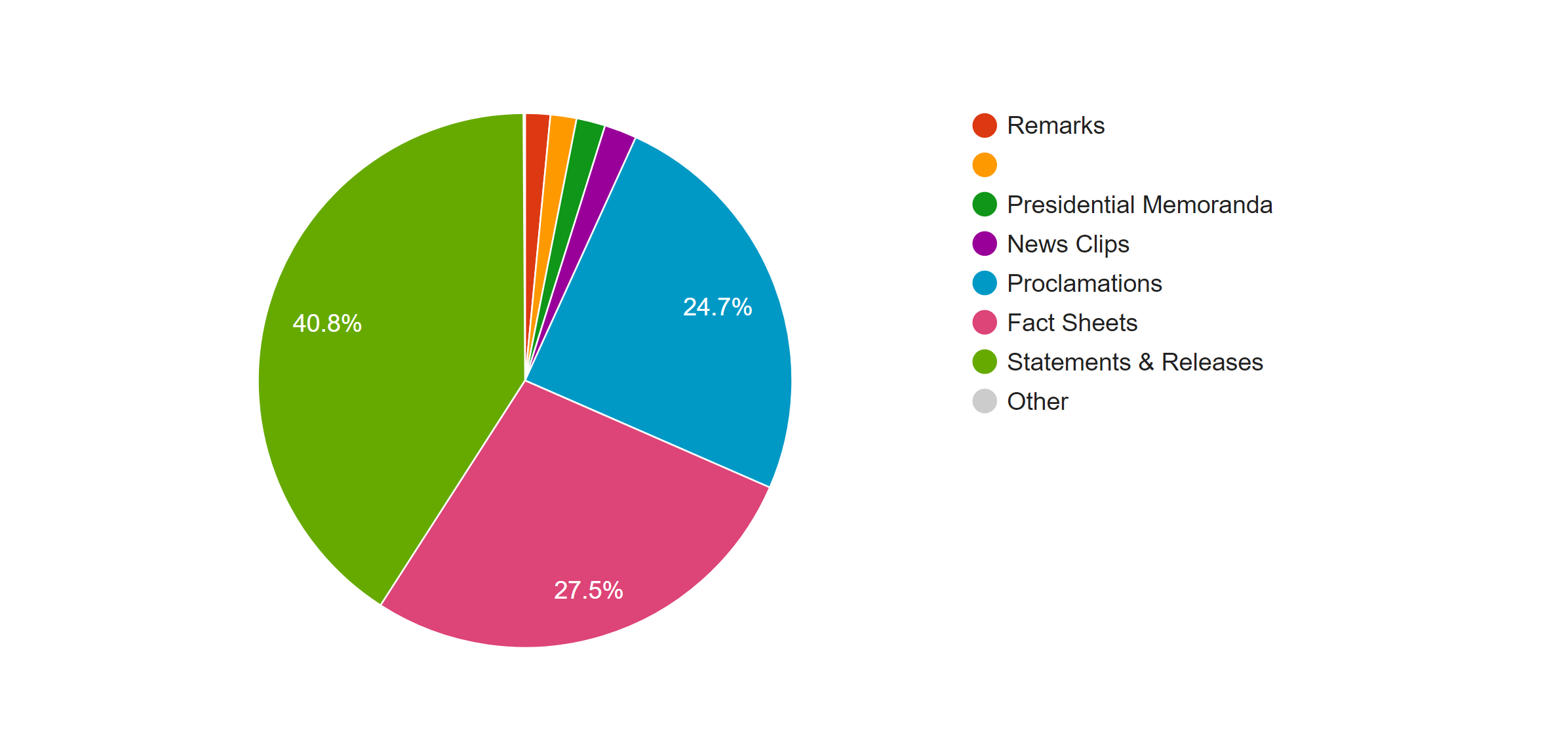
This pie graphs shows the distribution of the forms of news, the left one is based on the count of the files and the right one is based on the word count. In both graphs we can see that most of news is in the form of statement and releases. However, because the white house posted news through the internet, forms of news are not limited with the common form of new paper; many news was posted in the from of fact sheets or proclamations. By comparing the percentage of those two kind of forms in two graphs, we can see an obvious increase when they are counted with the number of words; therefore, news in those two forms is longer than that in the form of statement & release.
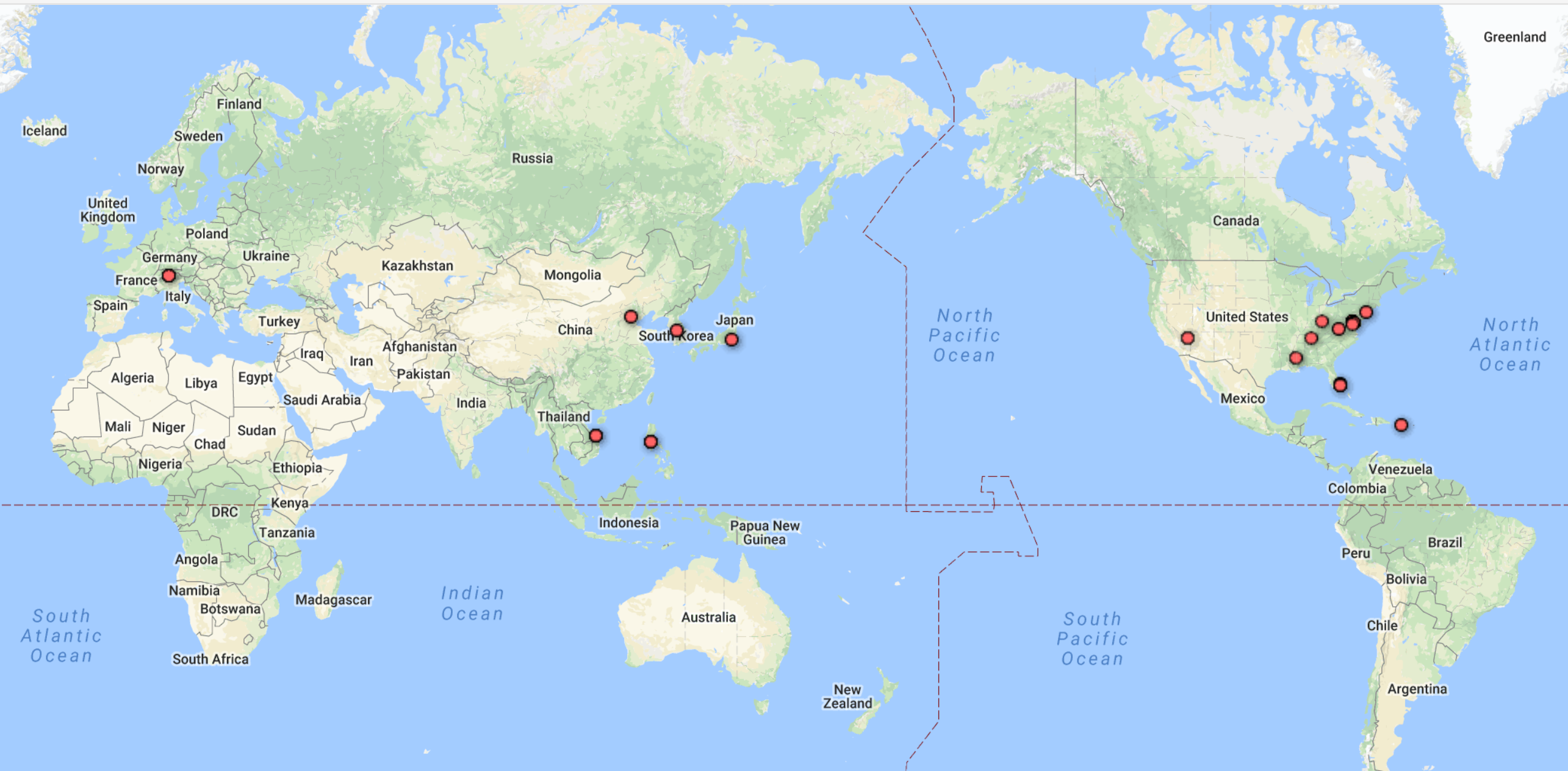
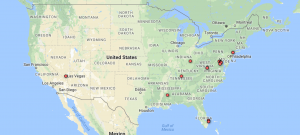
One advantage of Google Fusion is the map function of it doesn’t require the latitude and longitude of each location by analyzing the input string of data in location column. The left graph is the world map shows the which countries Trump visited from October 2017 to February 2018 and the map corresponding well with the fact that Trump visited several Asian countries in November last year. And in the left domestic graph, we can see that Trump visited more states in the west.
Palladio
Palladio is the tool I love best, even though the amount of tools provided is very limited. 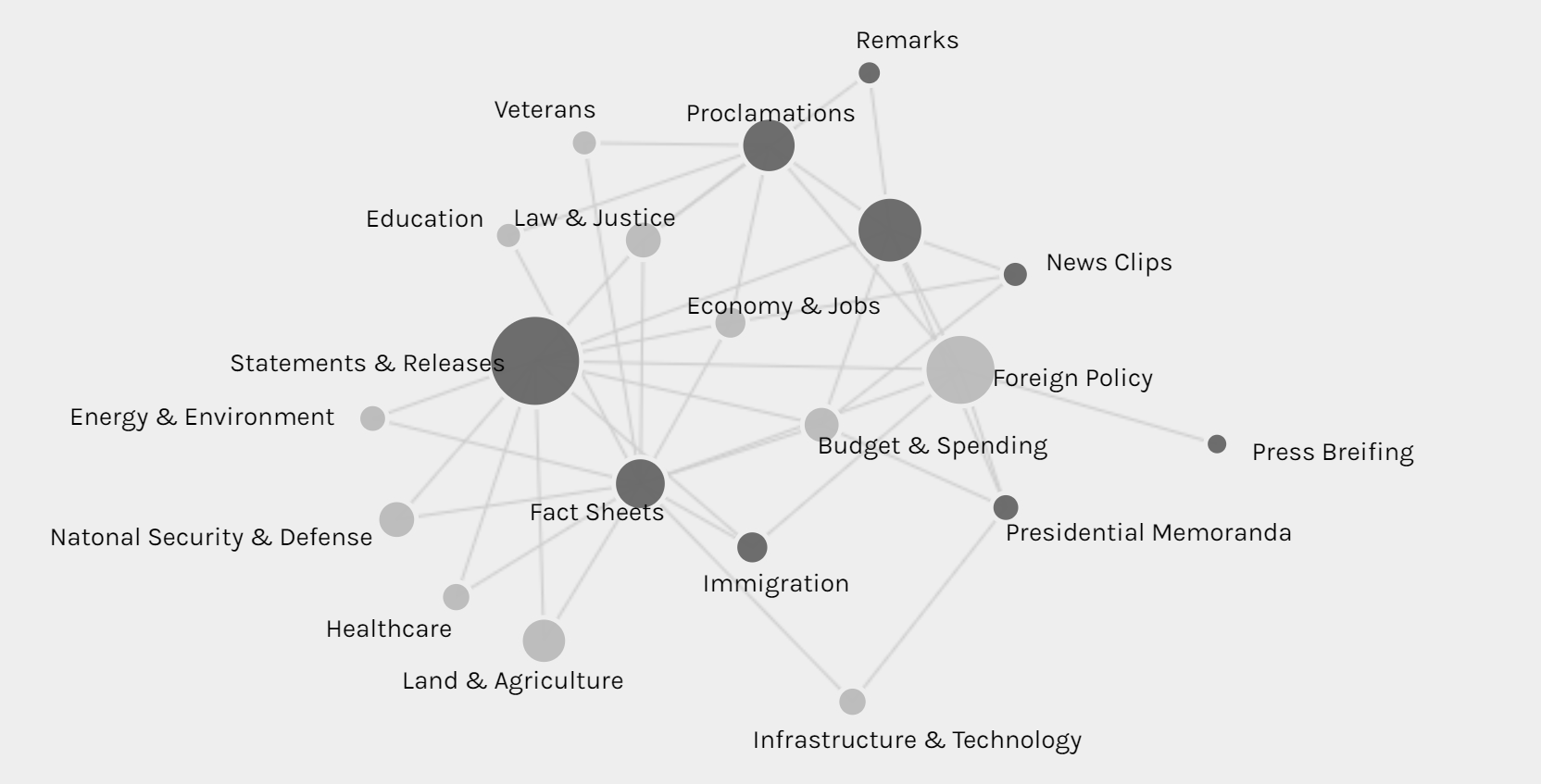
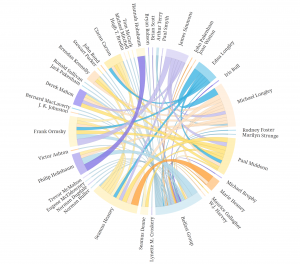
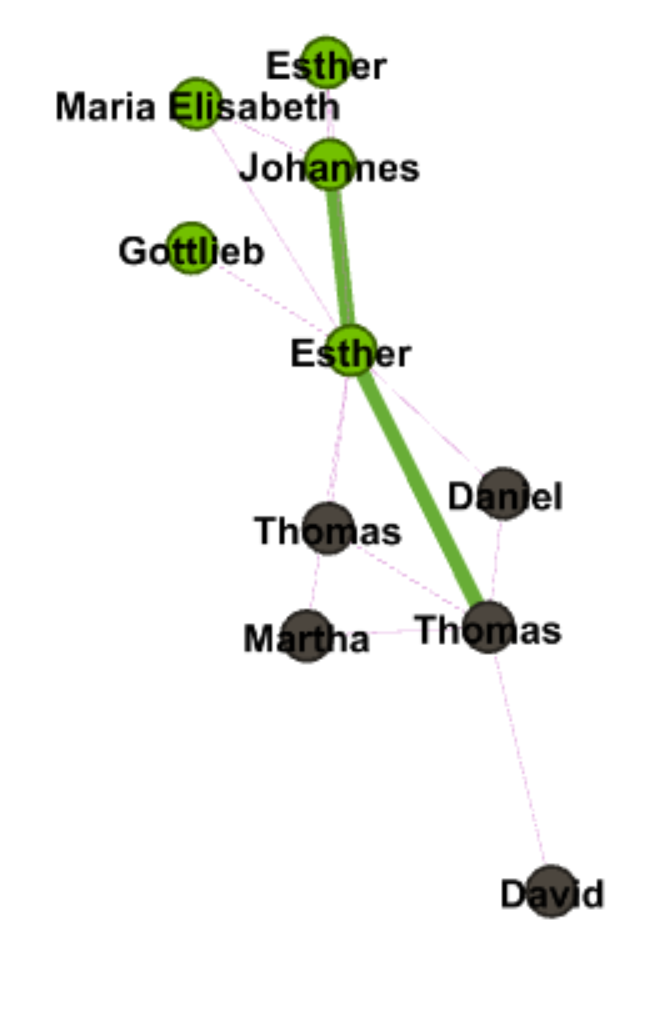
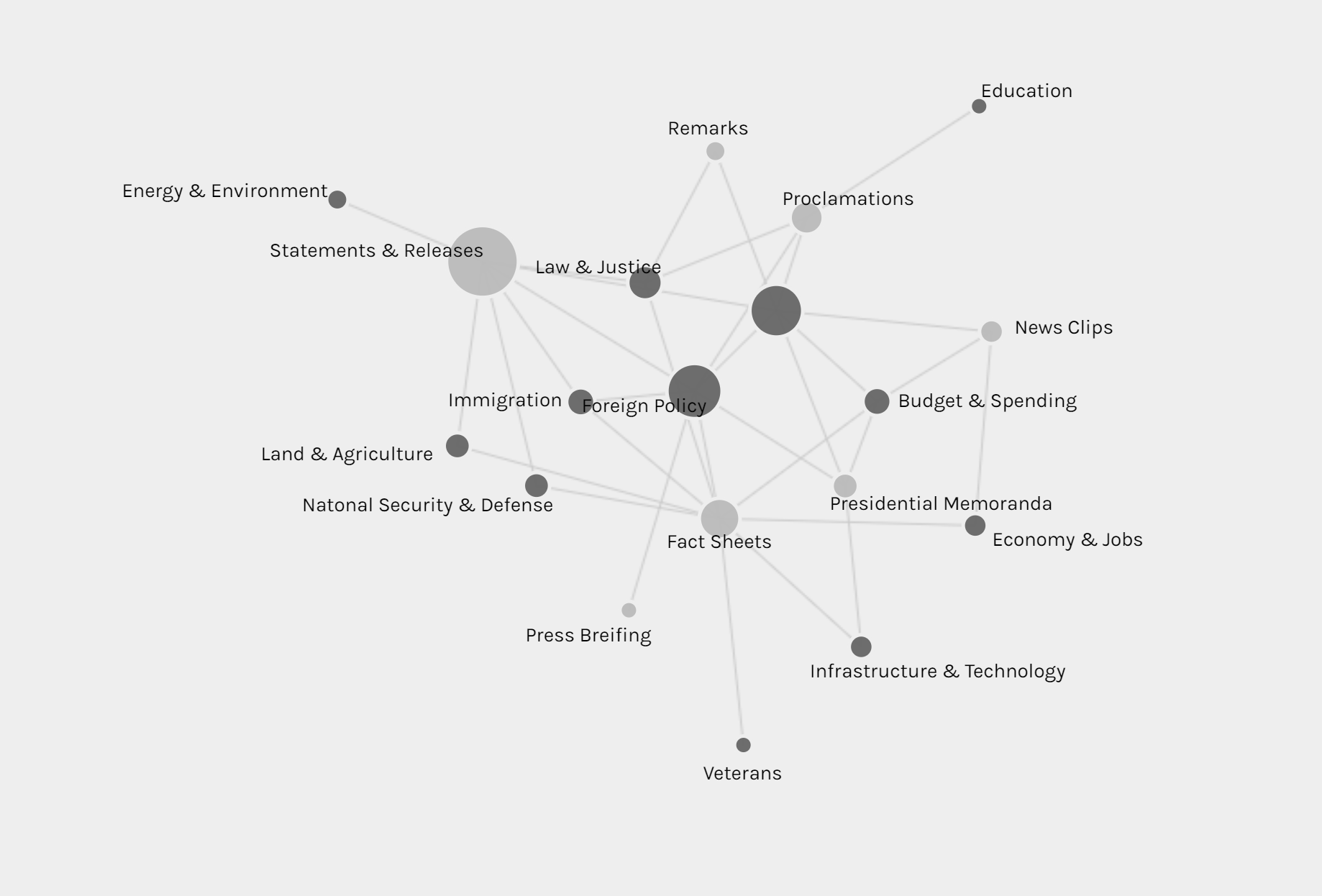
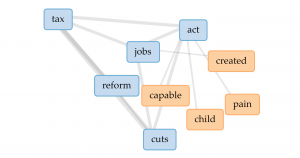
The network graph shows the connection between the forms and issues of news, so we can see different kinds of issues might be posted in preference of different forms, like infrastructure & technology’s news is usually in fact sheets or presidential memoranda instead of the most common form of statements & release.
The multi-dimension timeline tool in Palladio is the tool I love best. It fits well with my metadata form even though the news I collected was recorded in separated files. Palladio smartly groups files together and reveal the timeline graph by including the bar chart to show the distribution at the same time.
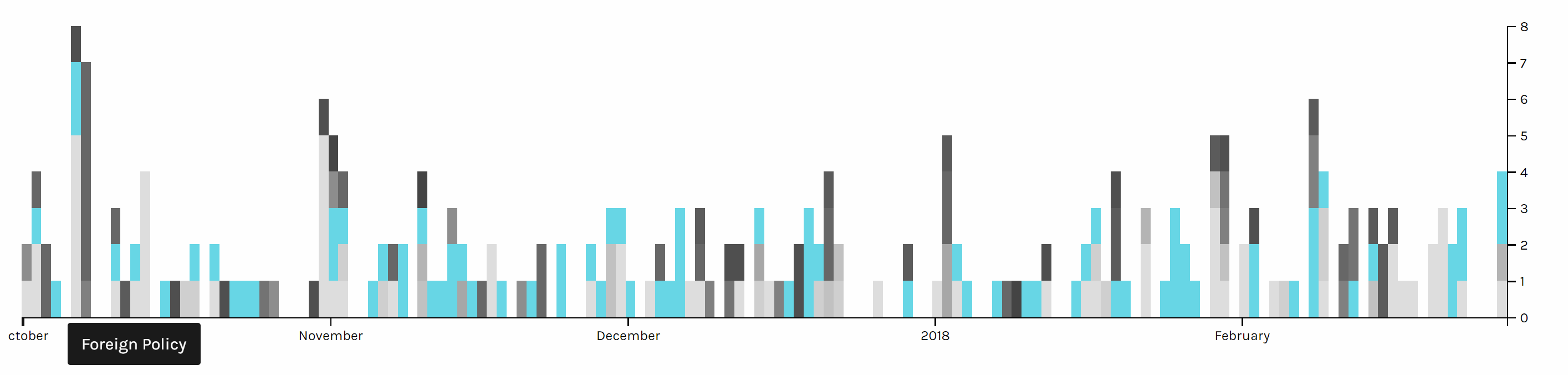
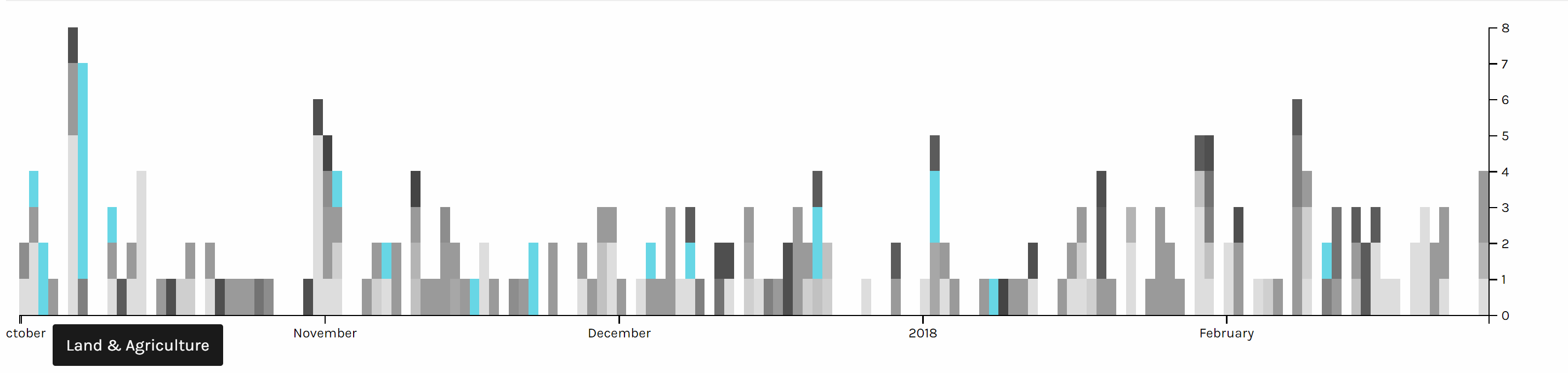
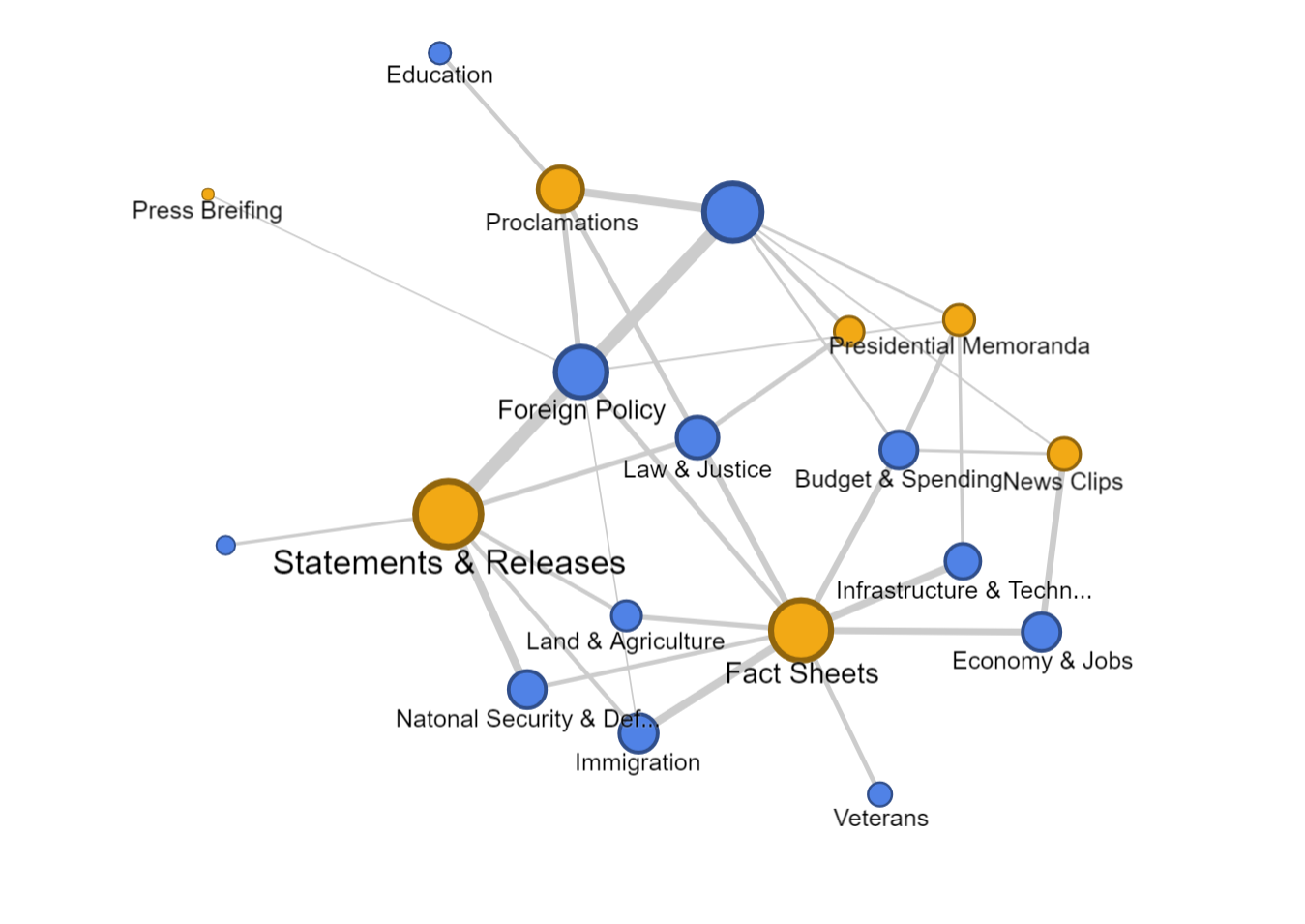
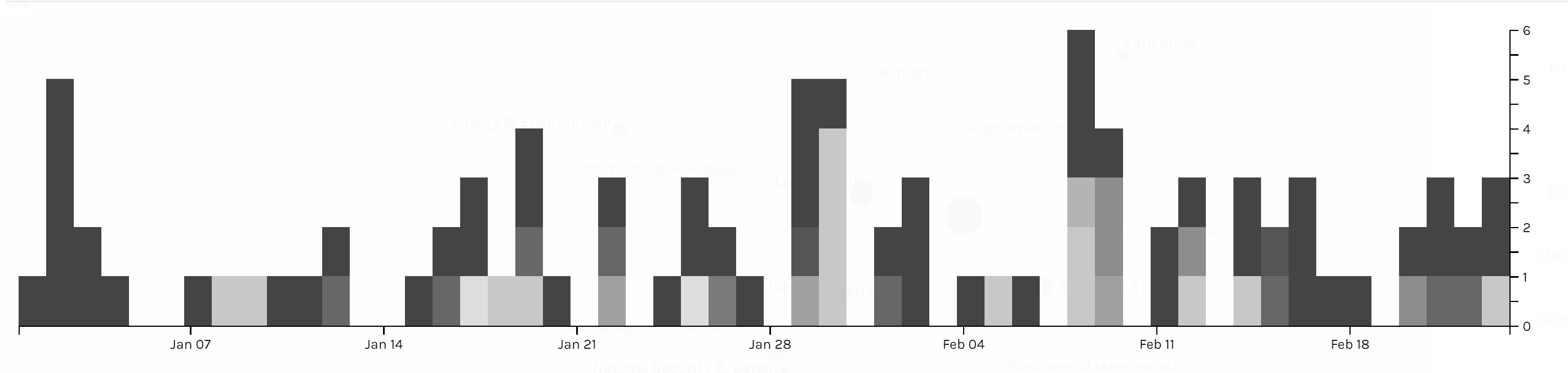
Two graph above are screen shots I took from the same chart but highlighted different issues. We can see foreign policy has been the top issue all the time. And land & agriculture is high particularly in the beginning of October 2017, because of the hurricane during that time.
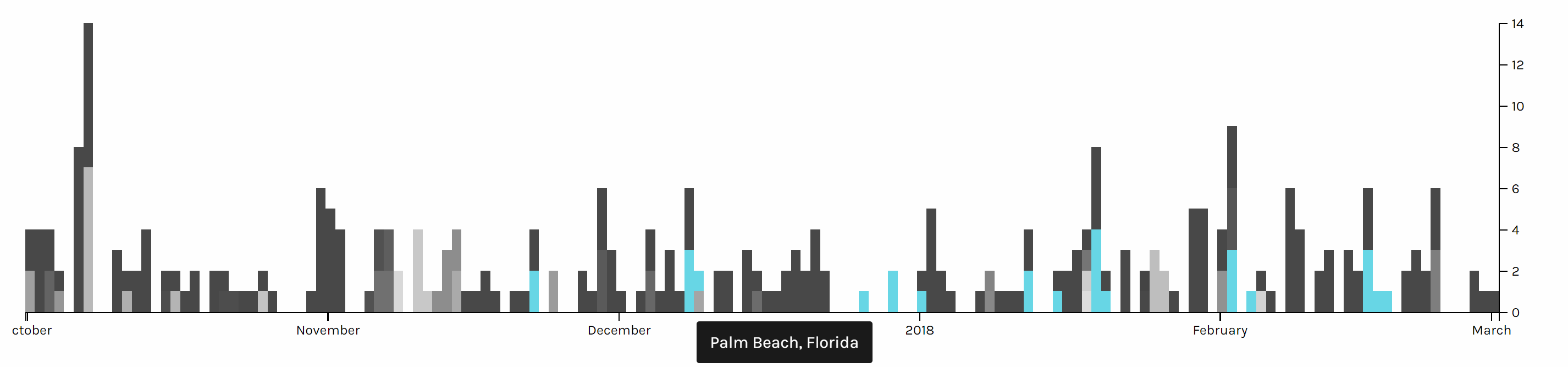
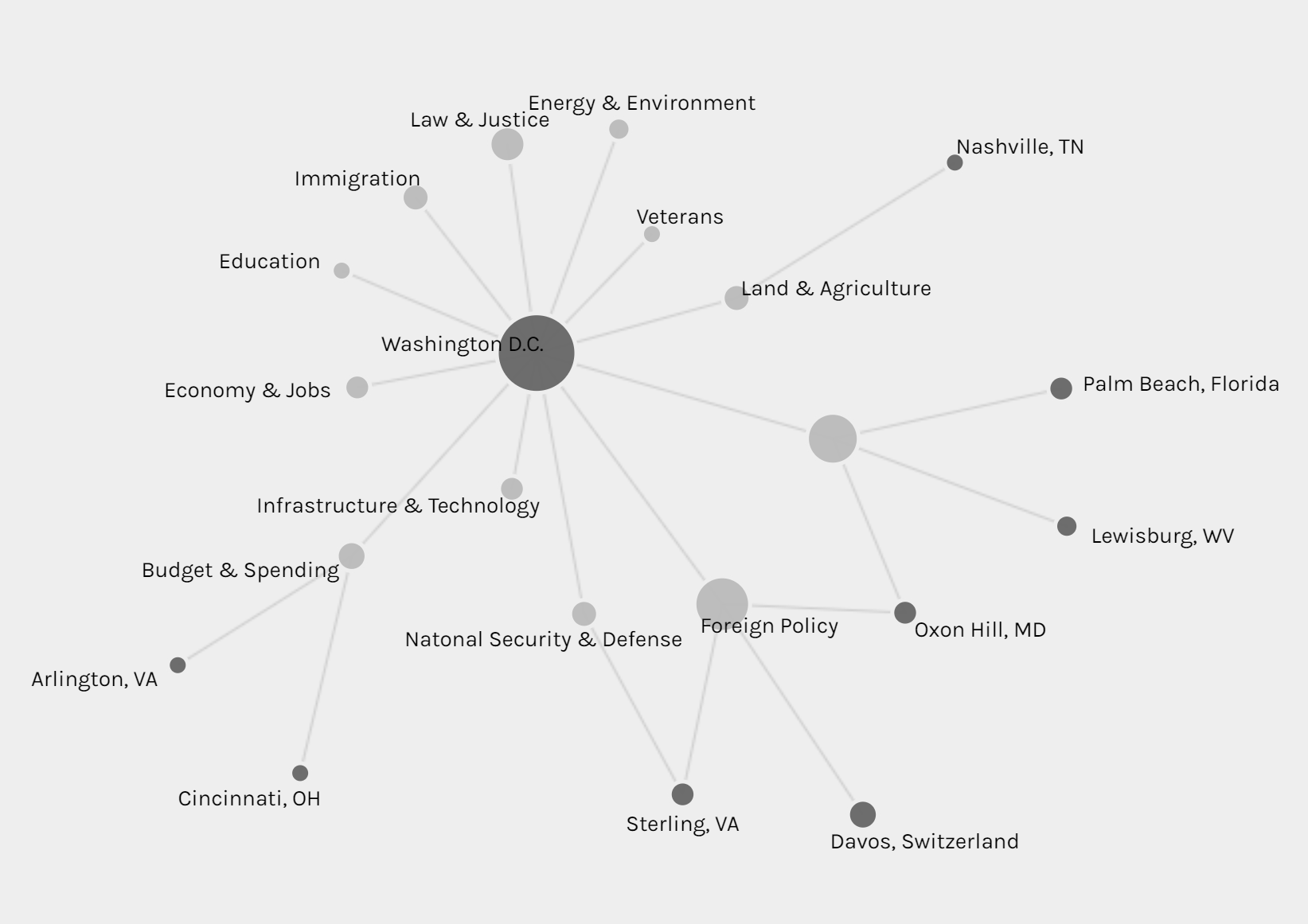
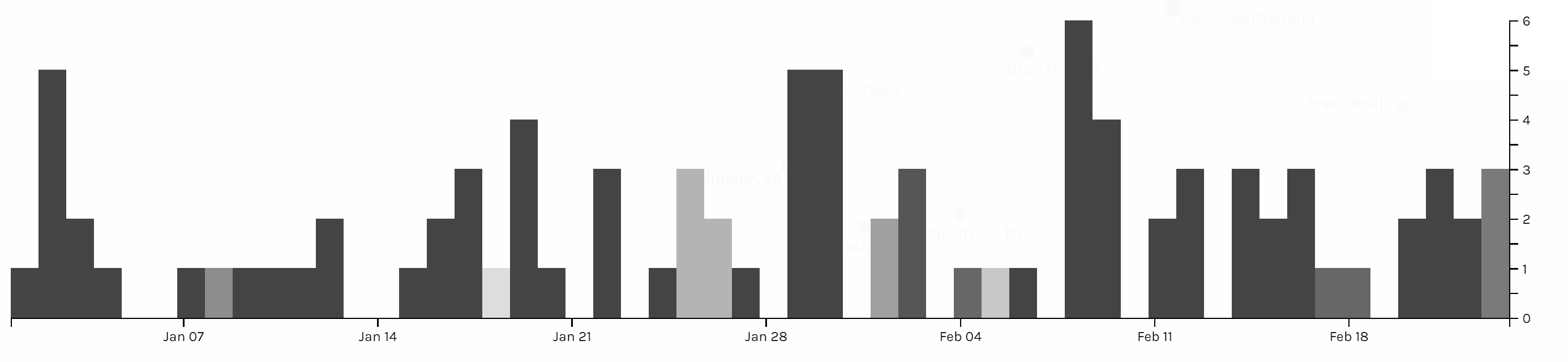
This timeline graph is produced based on the location of Trump and I highlighted when Trump is in Palm Beach, Florida, where Trump usually spends his holiday and plays golf. And it is obvious that Trump seldom visited October or November, when he might be busy with the hurricane and gunfire tragedy in Las Vegas in October and trip to Asian countries in November.
Voyant
Although both Google fusion and Palladio provide many useful tools for data visualization of my meta data, but to better understand the content of news, I also used Voyant for text analysis of my data. Voyant provide a lot of tools for text analysis and each has different advantages, but Voyant also has its limitations. The server of Voyant is very slow and there is limitation on the number of files I can upload, and when I uploaded a lot of files, Voyant starts to make serious mistakes. Fortunately, I took a look into my files, to check the word frequency, so I found this serious issue of Voyant and have to analyze data in separate months. Even though Voyant still helped me a lot in this final project to analyze the word use of news.
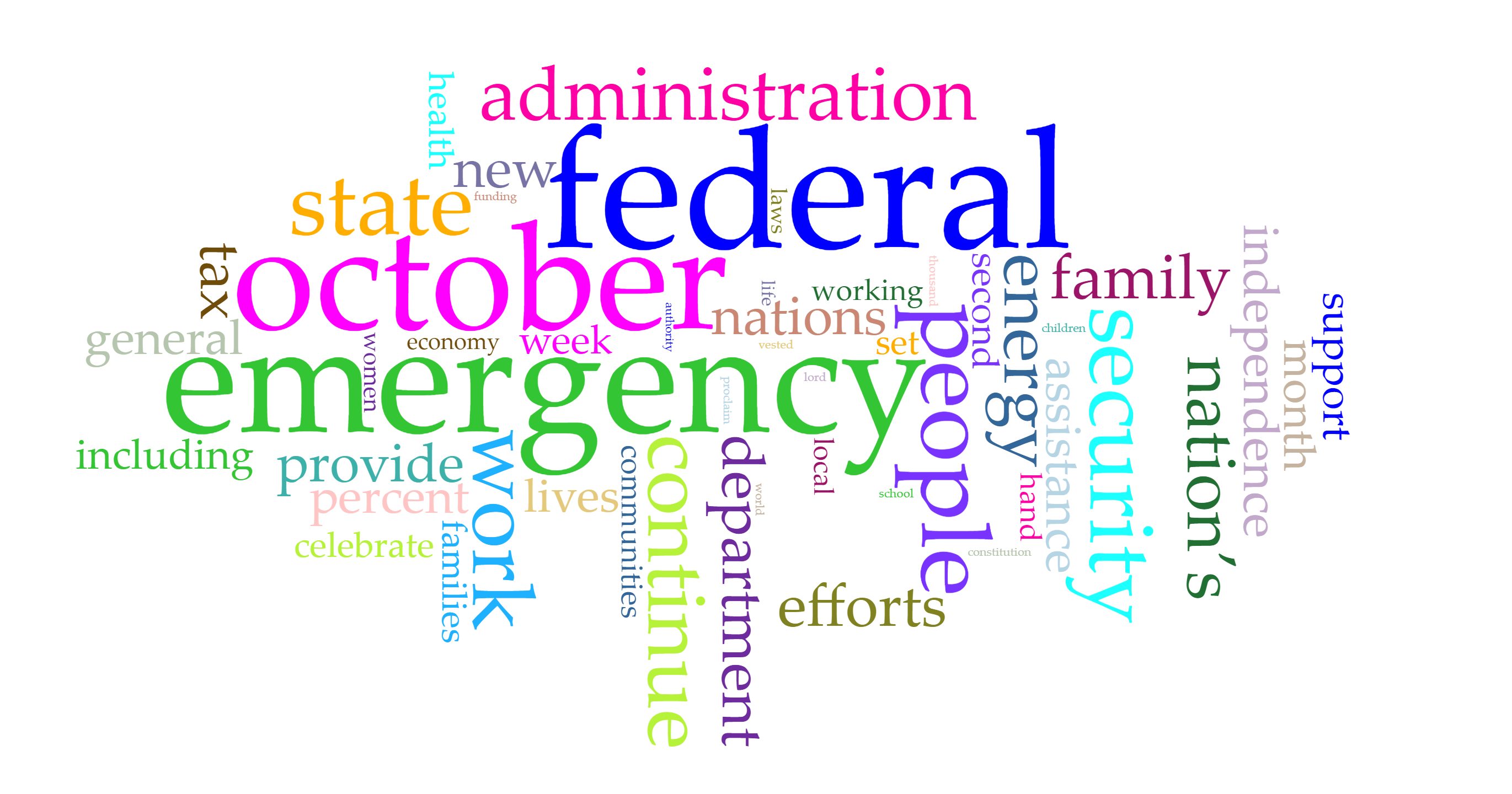
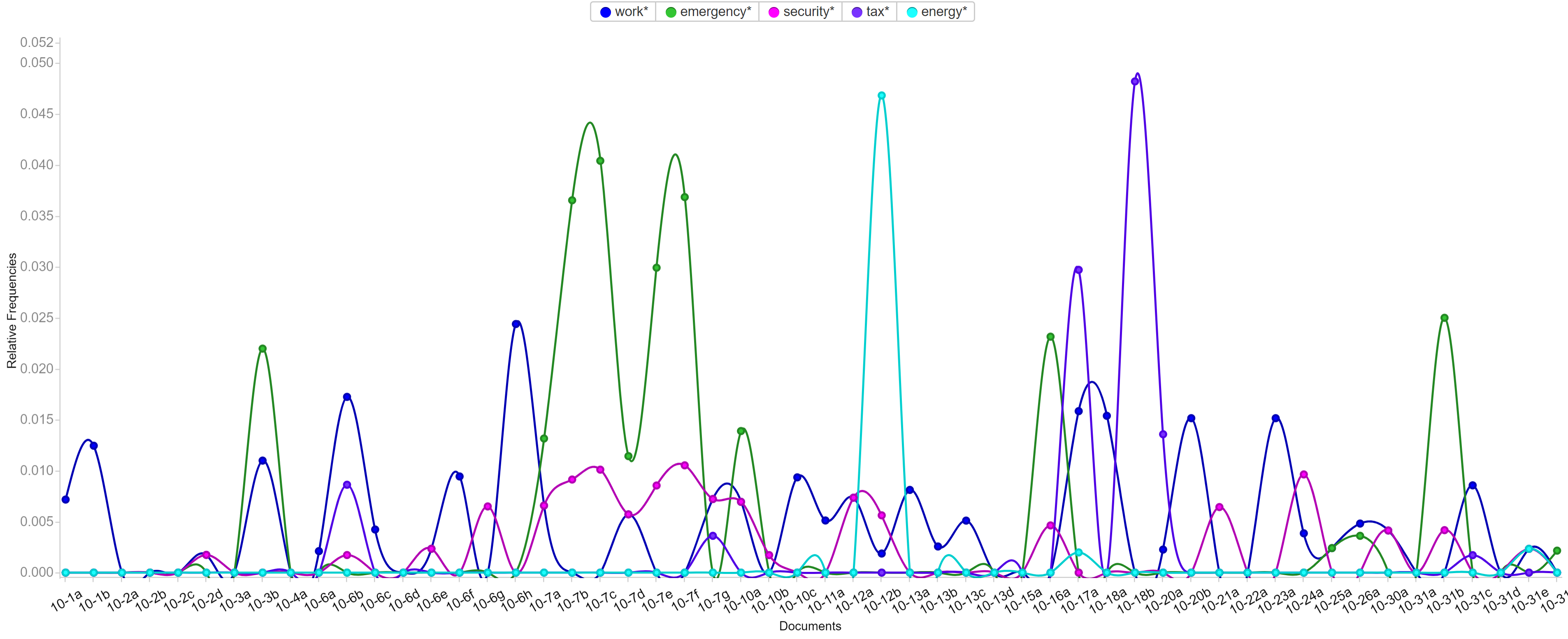
Voyant is very flexible that it allows users to edit the stop word list and pick the words users want to show in the trend graph. Words like emergency, security and tax have been most frequent in those five months and each months have different focused issues. By looking at frequently used words, it’s not hard to predict the top issues in each months. For example, because Trump came up with new job plan and tax cut, hurricane appeared and Las Vegas happened a gun fire tragedy, words like emergency, security, tax and job appeared most.
Conclusion
It was fun to do data visualization and I’m glad that I chose this course. During the process of my final project, I can better understand different data visualization tools and I learned that it’s more important to choose suitable tools and useful charts than just making fancy looking graphs. Gephi is a very powerful tool and I want to use it badly, but I also realize that my project focusing more on text and content instead of network, so I gave up using Gephi but tools like Google Fusion, Palladio and Voyant instead.







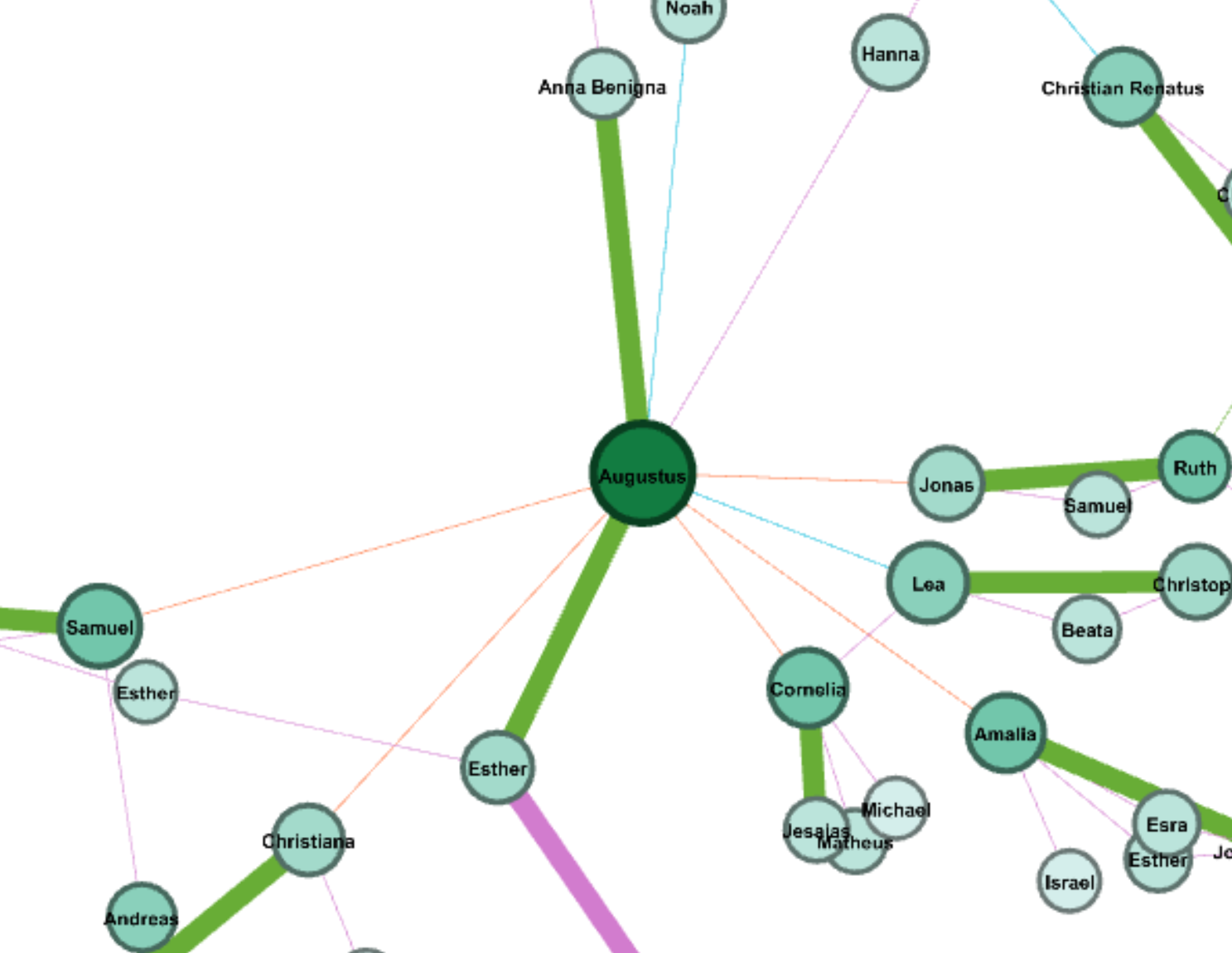
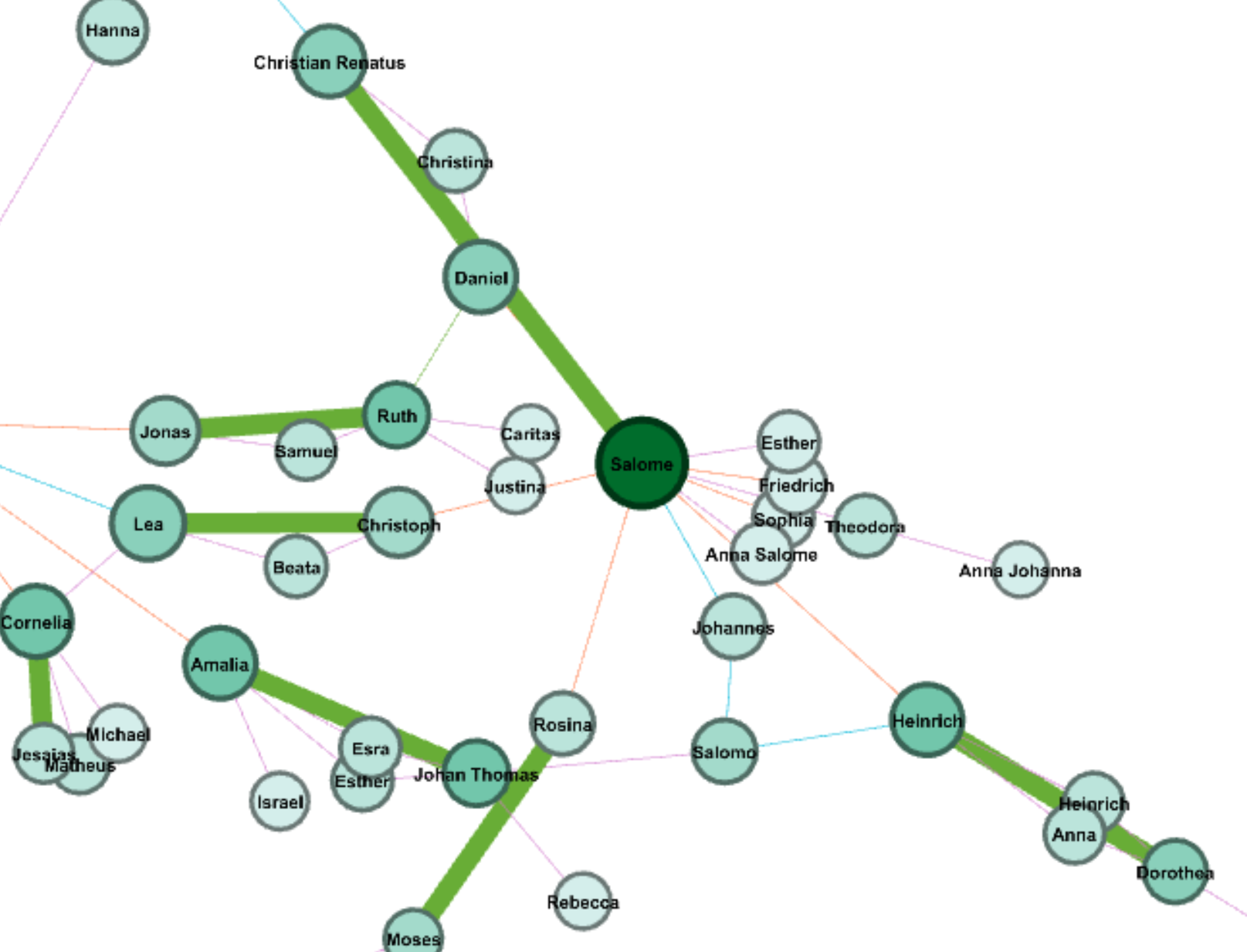
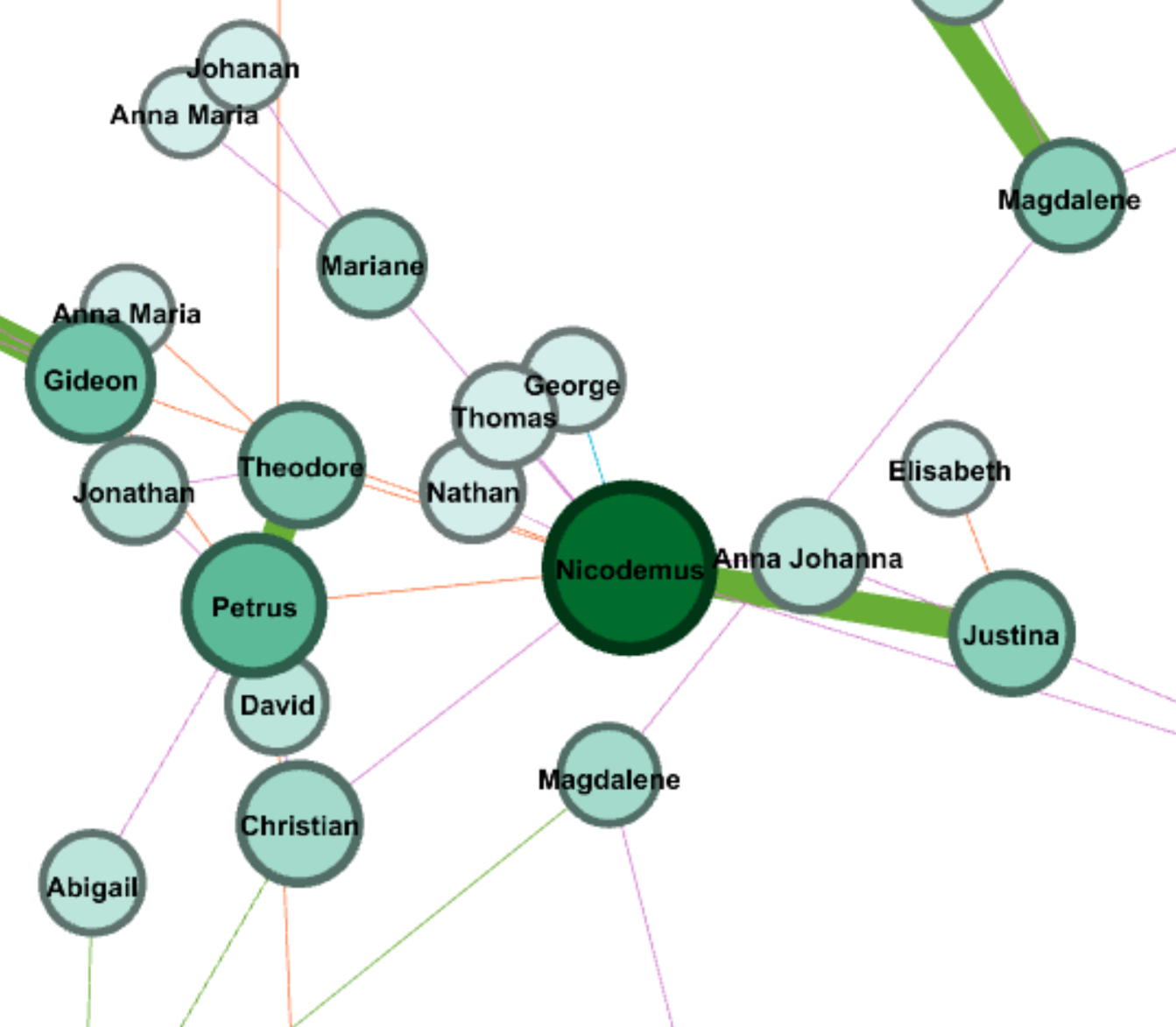
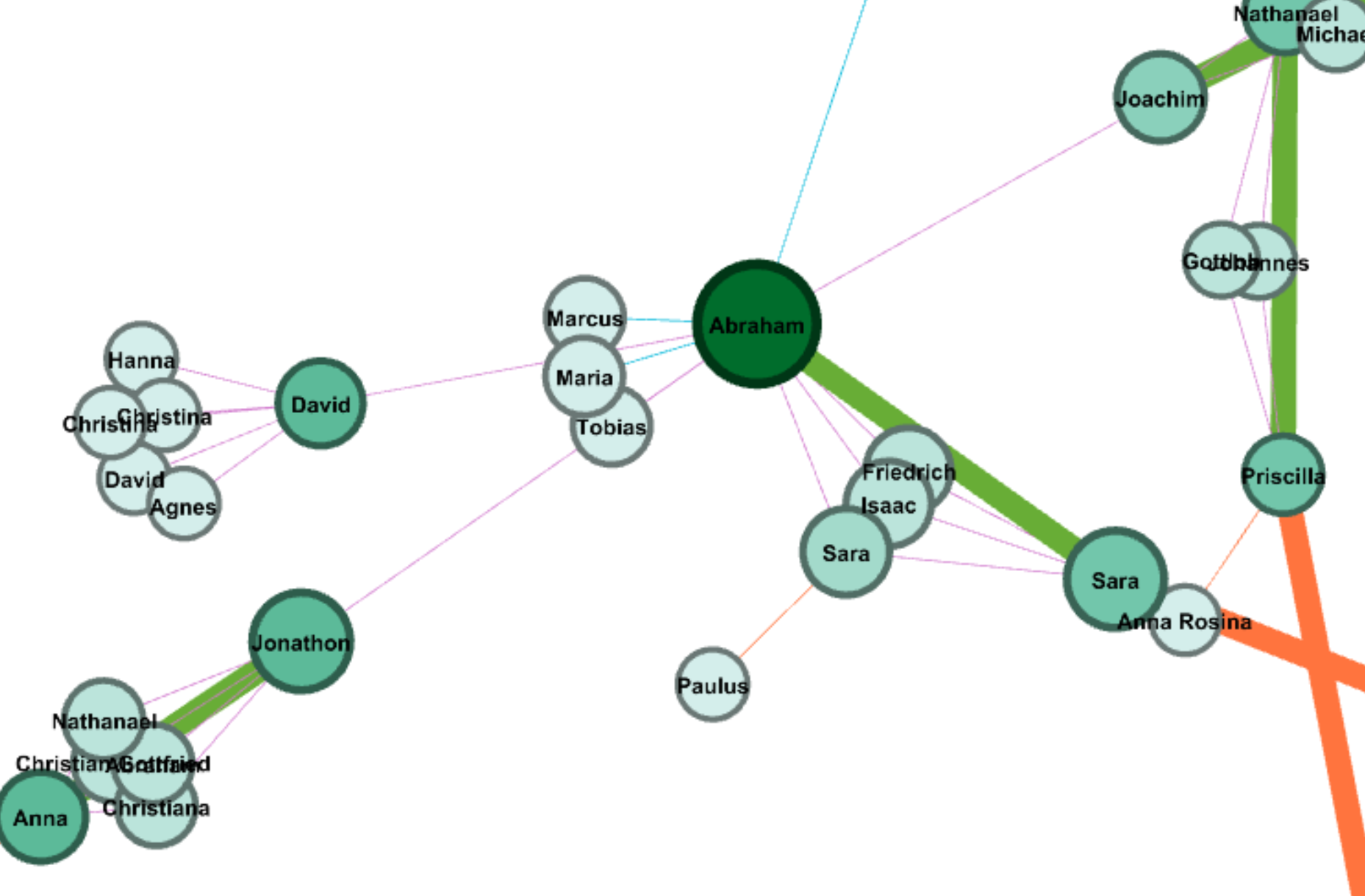

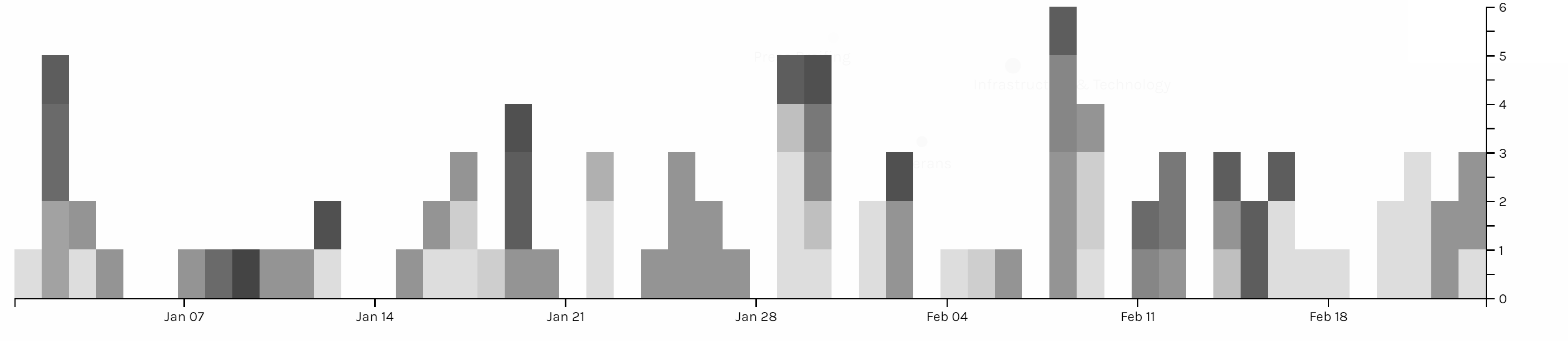







 (Sorry about high resolution of my computer, so the font size is extremely small)
(Sorry about high resolution of my computer, so the font size is extremely small)