Working with Jigsaw and Voyant
a.) After accepting the fact that corpus construction and visualization was, indeed, an iterative process (and that I would have to add nuance to my corpus throughout the semester), I decided to begin collecting journalistic articles from university newspapers regarding the firing of Joe Paterno. Although it appears that each article does not necessarily focus on Paterno’s firing, I decided it would be interesting to incorporate each publication’s first mention of the event (whether that was the overt focus of the article or not). I chose to gather articles from institutions that are connected to Penn State University either by proximity (UPenn, Bucknell, Pitt), athletic conference affiliation (Ohio State, Michigan, etc.), or level of football prestige (Oklahoma, Georgia, etc.). As my research with this corpus continues, I hope to remain cognizant of the subjectivity lurking behind article selection. My role as an archival author is just one factor that allows for the visualizations produced from my corpus to remain perspectival (simply by adding technology into the equation, essentialist understandings of this journalistic prose cannot be reached).
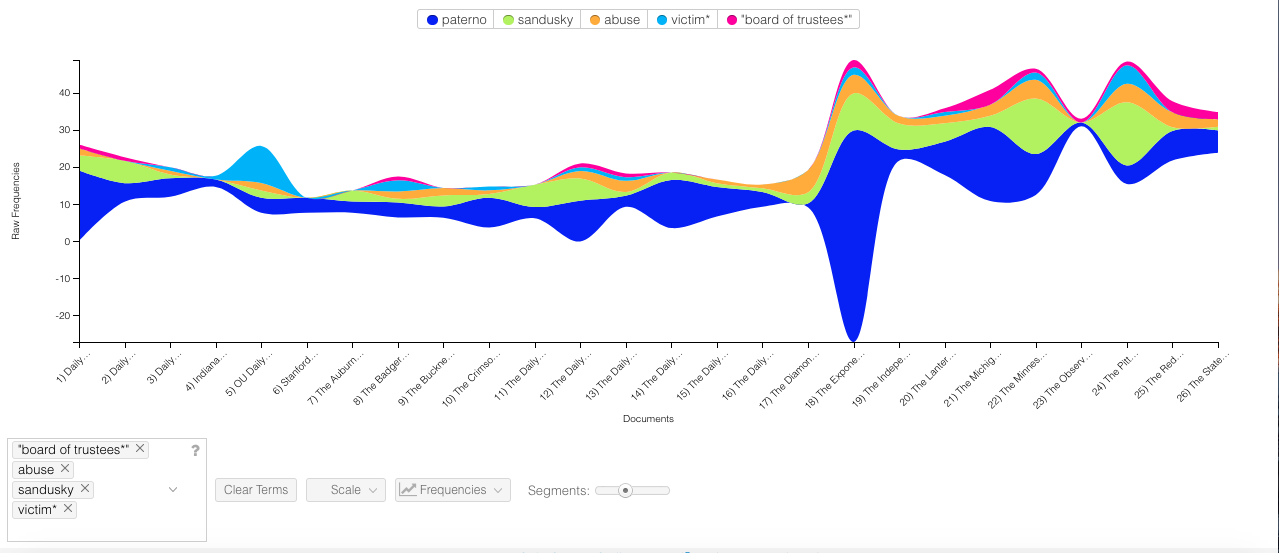
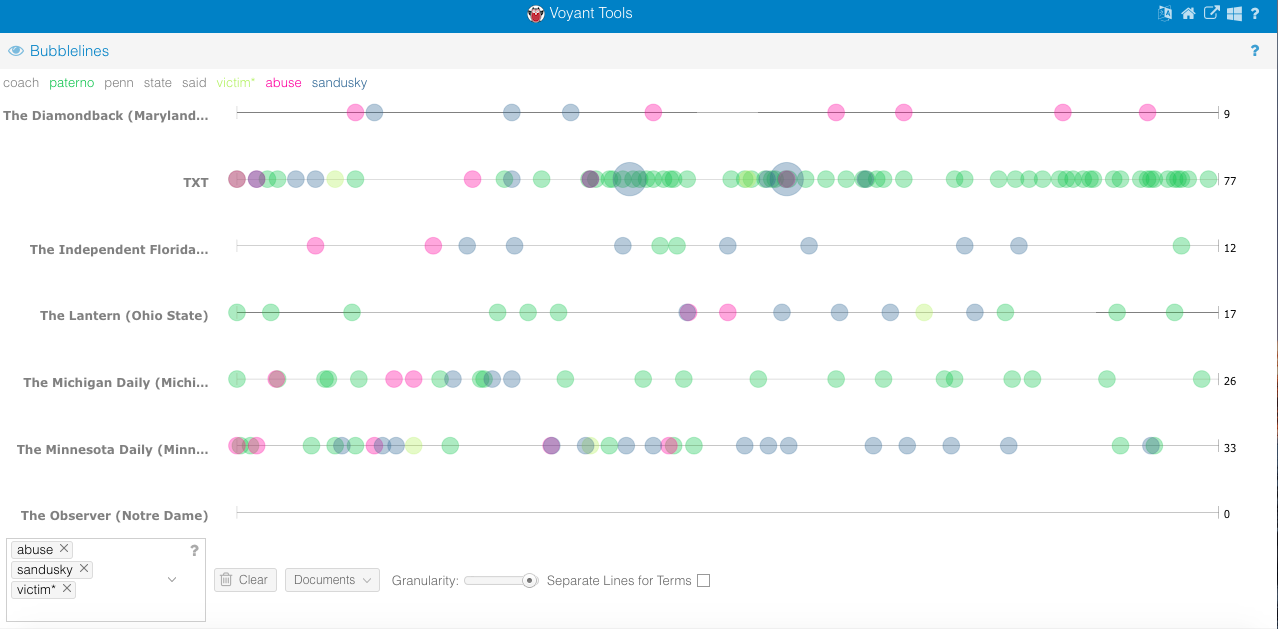
b.) Throughout my time working with the Voyant platform, I have appreciated it not only for its ability to foster more intimate understanding of meaningful entities, but also provide individuals with the opportunity to easily generate comparative research questions at the document level. In the two Voyant visualizations embedded (one being a Bubblelines visualization and the other a StreamGraph) one can begin to analyze occurrences of key entities as they relate to one another within specific documents and in the corpus as a whole. In particular, the raw word frequencies displayed in the StreamGraph visualization allowed me to to understand how different university news outlets framed the Paterno firing (ex: some did not even mention the board responsible for his firing and others). Two other interesting conclusions that can be drawn from the visualizations are that the victims of Sandusky’s abuse (the cover-up of which led to Paterno’s demise) rarely appear in this journalistic prose, but also that external campus news outlets (non-State College) do not shy away from connecting Paterno and Sandusky, leading to an implicit association shrouded in negativity.
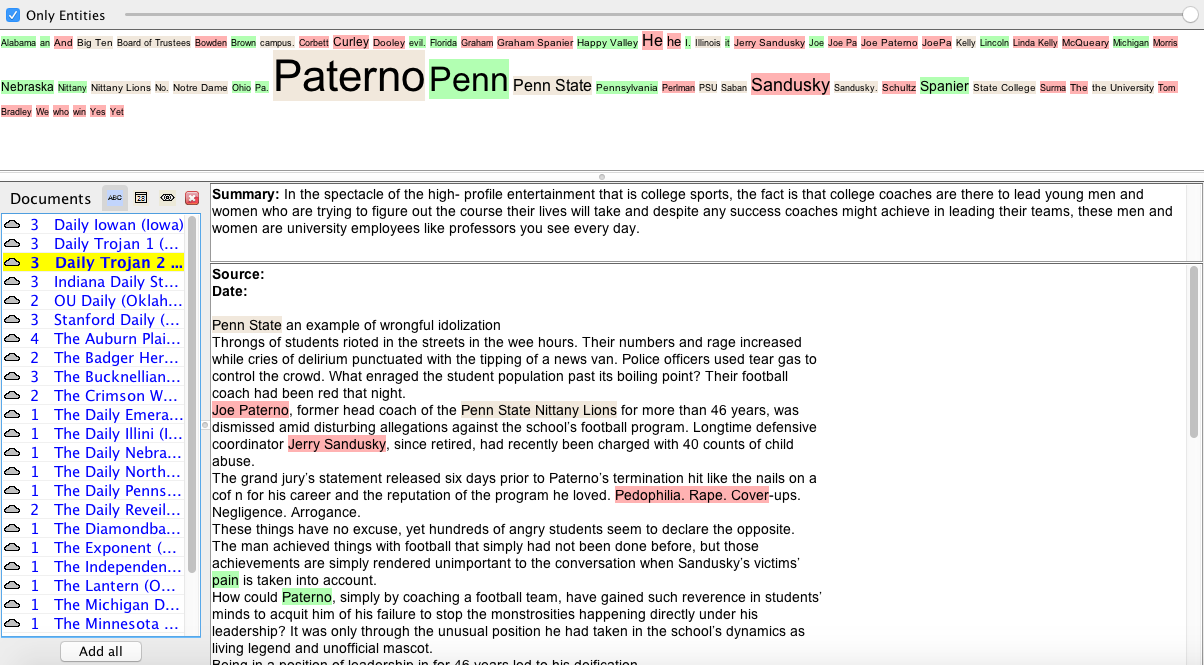
c.) One of the most meaningful visualizations I was able to produce using the Jigsaw platform was the WordTree displaying appearances of “Paterno” throughout my corpus. By expanding my capacity for entity contextualization, this tool afforded me the opportunity to begin to discern community level sentiment displayed in nominal data consisting of journalistic prose of publications external to PSU. Meirelles effectively summarizes the value of a WordTree visualization for analysis in her sixth chapter, “Besides preserving the context in which the term occurs, the method also preserves the linear arrangement of the text” (Meirelles 200). While functioning in this way, the WordTree visualization manifests itself as a more intermediate step in distancing oneself from a text. By quickly allowing me to understand the context in which JoePa’s name showed up, the Jigsaw platform helped me to see that university newspapers outside of State College did not shy away from criticizing Joe Paterno for his role in the Sandusky scandal, but also felt the need to show appreciation for his accomplishments as a coach (things that may aid in blinding the Penn State community to his wrongdoing). The image of Jigsaw’s Document View exemplifies the platform’s ability to further remove researchers from their corpus and garner an understanding of entity frequency and classification all while summarizing documents (although the selection of these statements by the program may also be an example of non-objectivity in data provision).
d.) In terms of commonalities, each of these programs has the ability to generate meaningful visualizations that allow for the contextualization of entities (ex: seeing connected words, etc.) and understanding of word frequency (which can be extrapolated to fit perspectival analysis). Obviously, each platform also possesses characteristics which its counterpart lacks. For example, Jigsaw can easily generate visualization of sentiment while Voyant offers remarkably unique and varying visualizations of word frequency (ex: bubble sizes, word sizes, stream width). It has also become rather apparent to me that individuals choosing to work in the Jigsaw platform must have a more intimate understanding of their corpus in order to create visualizations, as more “work” must be done to produce meaningful images. However, once one is familiar with the platform, I am under the impression that Jigsaw allows for more advanced visualization of entity context and document connection. All in all, Voyant provided me a more preferable method for discerning patterns regarding word frequency (allowing me to address sentiment and entity relationships). Jigsaw, on the other hand, allowed me to produce detailed WordTree visualizations that worked as a sort of additional approach in bolstering conclusions regarding outsider perception of Paterno (bigger picture as opposed to entity-level).
e.) Simply put, by engaging with both my corpus and the textual analysis platforms Jigsaw and Voyant, I have learned there are many opportunities for argumentation and subjective involvement in digital humanities research. In this way, I have learned to appreciate the role of technology in expanding the capabilities of nominal data analysis, but also understand that the implementation of digital methods into digital humanities does not generate essentialist interpretations (I now actually see where I could have gone in different interpretive directions). As Clement puts it, “Sometimes the view facilitated by digital tools generates the same data human beings (or humanists) could generate by hand…At other times, these vantage points are remarkably different from that which has been afforded within print culture and provide us with a new perspective on texts that continue to compel and surprise us by being so provocative and complex — so human” (Clement 12). What can be gleaned from this quotation, and my work on this assignment is that digital humanities does, in fact, involve a give and take between subjective and objective construction. By utilizing differential reading strategies and accepting the interaction of close and distant reading, researchers such as myself will be properly equipped to read and contextualize readily accessible and more distant digital findings (and acknowledge subjective intervention in text selection, platform construction, etc.).